

AI-Steve Deep Dive
When personal AI becomes an extension of intellect

By Steven Muskal | January 30, 2026 | Technical Analysis + Personal Narrative
Meta-Note: This post was partially generated through AI Steve’s own capabilities, as a demonstration of how the system has become sophisticated enough to help document its own architecture and impact. The irony is not lost: an AI trained on four decades of reasoning patterns now helps articulate those very patterns.

I. The Origin Story: From Grief to Innovation
In early 2025, my father, James B. Muskal, passed away at 86. Like many sons, I found myself sifting through decades of email exchanges, legal documents, and memories, with a persistent frustration: so much wisdom, humor, and careful reasoning was trapped inside static files.
That frustration became the catalyst for AI Dad, an artificial intelligence system designed to reconstruct my father’s intellect using Retrieval Augmented Generation, or RAG.
AI Dad was only the beginning.
What started as a memorial project evolved into something far more ambitious: AI Steve, a comprehensive personal AI assistant that does not simply answer questions. It amplifies my reasoning patterns, surfaces forgotten context, and increasingly behaves like an extension of how I think.
The core insight is simple.
Personal AI assistants are not just productivity tools. When trained on decades of your own data, they become mirrors of cognition: systems that reflect and amplify your intellectual patterns, creating a feedback loop between human and machine reasoning.
II. The Neural Network Lineage: 1991 to 2026
To understand AI Steve, you need to understand that my relationship with neural networks spans more than forty years. This is not a recent fascination. It is the through line of my career.
Key Milestones
1988: B.Sc. Engineering Chemistry and Computer Science, Colorado School of Mines
1989: Met Kirsten Petersen at UC Berkeley
1991: Ph.D. Chemistry (Biophysical Chemistry), UC Berkeley, neural networks for protein structure prediction
1991: Product Manager and Senior Scientist at MDL
1995: Director, Scientific IT and Unit Director at Affymax / Glaxo Wellcome
1996: Married Kirsten Muskal (May)
1997: Daughter Lili born (October)
2000: Daughter Hannah born (April); CTO and VP Informatics at Libraria
2003: Founded Sertanty Inc. / Eidogen Sertanty
2011: Mother Sybil passed (June)
2018: Sister Julie Muskal Schirmacher passed (November)
2025: Father James B. Muskal passed; inspiration for the AI Dad project
2025: AI Dad and AI Steve became full production systems
2026: AI Steve is now the daily cognitive system described here

The 1991 PhD Thesis: Neural Networks for Protein Structure Prediction
My doctoral work at UC Berkeley under Sung Hou Kim focused on using early neural network architectures to predict protein structural features from amino acid sequence. This was 1991, long before the deep learning revolution, long before GPUs made neural networks practical at scale, and long before transformers and attention mechanisms entered common vocabulary.
We were using neural networks to detect patterns in amino acid sequences that predicted secondary structure: alpha helices, beta sheets, and coil regions. The challenge was not only network design. It was understanding which patterns were meaningful in biological systems, then validating those predictions against ground truth.
Our work built on pioneering research by Qian and Sejnowski (1988) and Holley and Karplus (1989). That lineage continued after my thesis. Dubchak, Holbrook, and Kim (1993) built directly on this approach, demonstrating how early neural network methods could extract structural signal from sequence alone
Why does that matter for AI Steve?
Because the intellectual framework I developed more than three decades ago - pattern recognition, feature engineering, validation against ground truth, and disciplined handling of noisy data - is the same framework embedded in AI Steve’s architecture today.
The Career Arc: From Proteins to Personal AI
1991–1995 (MDL): Computational methods for molecular design and informatics
1995–2000 (Affymax / Glaxo Wellcome): Scientific IT infrastructure for drug discovery
2000–2003 (Libraria): CTO and VP Informatics, scaling ML in biopharma
2003–present (Eidogen Sertanty): AI driven drug discovery, kinase modeling, structure based design, toxicity prediction
2021–2024: Advisory roles at AI focused companies
2025–2026: AI Dad and AI Steve, applying decades of methodology to personal knowledge, legacy, and daily workflow
The throughline is pattern recognition in complex systems. Protein structures, molecular interactions, and human communication differ in subject matter, but the methodology remains consistent: train on rich data, validate against reality, and iterate based on feedback.
III. AI-Steve Architecture: Technical Deep Dive
AI Steve is not a chatbot. It is a multi source RAG system with temporal awareness, contextual learning, and defensive safety mechanisms designed to enforce data fidelity.
At a high level, AI Steve is a memory system before it is a language system.
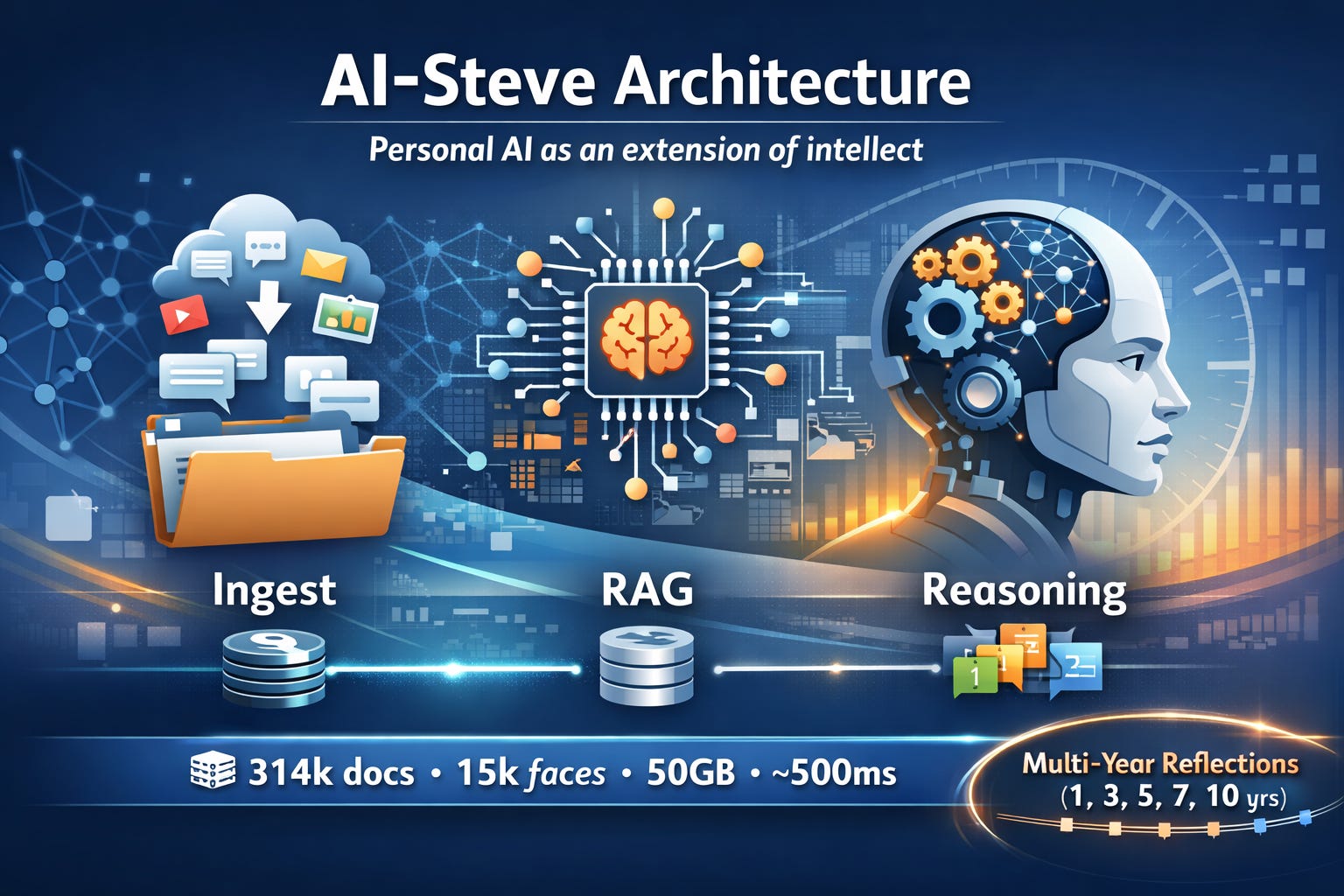
The Data Pipeline: From Inbox to Insight
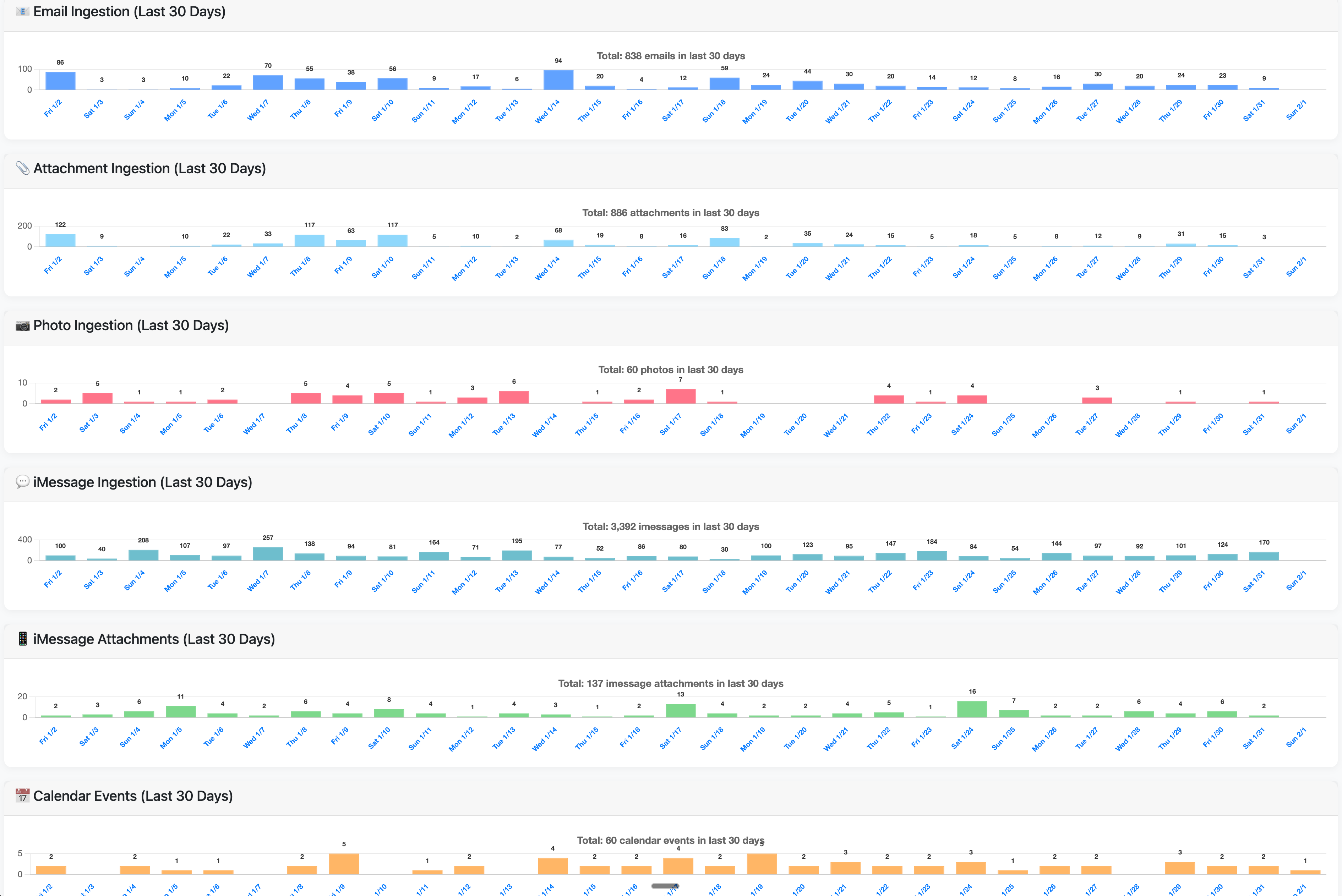
Continuous ingestion
A file watcher polls every 60 seconds and monitors email, iMessage, calendar, photos, and health exports.
Content processing
Context aware chunking, embeddings using OpenAI text-embedding-3-small, and rich metadata capture.
Storage: PostgreSQL plus pgvector
Vector similarity search with temporal indexing and source type filtering.
RAG retrieval engine
Multi vector retrieval with dynamic contextual weighting.
LLM generation
Claude Sonnet 4.5, with strict data fidelity rules and optional citation tracking.
Response delivery
Web app, email workflows, and optional voice interface.

The Seven Anti-Hallucination Rules
This is where decades of scientific rigor show up in code.
Trust Steve’s data over general knowledge
Quote specific values
Cite sources
Flag counterintuitive findings
Distinguish correlation from causation
Admit uncertainty
Sanity check before responding
These rules encode scientific validation discipline directly into system behavior.
IV. Code Directives: Prompt-to-Code Automation
Perhaps the most ambitious feature in AI Steve is Code Directives: a domain specific, prompt driven code generation engine that turns natural language into executable code.
Sometimes you do not need another paragraph. You need a program.
How It Works
A subject line like:
droid code 1312Appraisal build an appraisal for 1312 N Astor St
triggers a predictable flow:
The system detects a directive and routes it into the code generation path
The request is classified into one of nine production domains
A prompt is assembled from YAML (“Yet Another Markup Language”) configurations, using base templates plus domain specific templates
Code is generated by the selected agent (Droid by default, Claude or Codex as configured)
A peer review layer runs AST (Abstract Syntax Tree) based safety checks and triggers regeneration if violations are found
Execution occurs in a sandboxed workspace with a strict timeout and controlled package installation
A self healing retry loop uses error feedback to improve the next attempt, up to a defined limit
Results are delivered as a report with embedded charts, data files, and logs

The nine domains
Real Estate: property appraisal, comparable analysis, market data
Scientific: literature research, PubMed workflows, protein and gene data, paper summaries
Finance: stock analysis, sentiment tracking, portfolio monitoring
Biography: person research, due diligence, relationship mapping
Contracts: contract analysis, invoice tracking, document review
Wellness and Health: meal planning, fitness routines, personal health correlations
Business Intelligence: email analytics, communication patterns, operational summaries
General: catch all for miscellaneous tasks
Computational Biology: protein analysis, model training, ML projects
Each domain uses YAML templates with validation rules, recommended libraries, and special constraints.
Peer Review: Safety Through AST Analysis
Before any code executes, it passes through a multi-stage peer review system.
AST (Abstract Syntax Tree) violation detection scans for patterns such as fabricated data, synthetic entities, or silent error swallowing. If critical violations are detected, the code is sent back for regeneration. Non critical issues can be auto fixed. If critical violations persist after multiple attempts, execution is blocked.
This is defensive engineering. It accepts that LLMs can hallucinate, and builds systematic checks to catch hallucinations before they run.
V. Face → Health: Vision as a Longitudinal Signal
Code Directives gave AI Steve the ability to act. Face → Health gives it the ability to observe, over time, in a disciplined way.

The face is treated as a sensor, not a narrative.
Face → Health does not diagnose. It does not infer emotion. It evaluates weak visual signals only through longitudinal correlation.
Why Face → Health exists
Health data already exists. What was missing was a time anchored visual snapshot.
By linking daily face images to same day physiology and next night sleep outcomes, AI Steve gains a new form of temporal self awareness.
What is implemented in production
Face to Health is fully integrated into AI Steve’s ingestion and retrieval pipeline.
Health export face images are detected automatically and stored with strict date normalization. Each image is processed through a specialized vision prompt focused on wellness relevant cues such as alertness, facial tension, hydration, and stress indicators. The outputs are saved as structured annotations alongside the image.
Each face is embedded twice. CLIP embeddings enable image similarity and clustering. Face embeddings enable identity specific retrieval. A dedicated health record date field links every face to the corresponding Apple Health daily record.
As a result, health faces appear naturally throughout the system: in image search, in face search, attached to daily health summaries, and in a materialized database view designed specifically for machine learning and correlation analysis.
Temporal correctness is enforced at ingestion. No retrospective relabeling. No inferred dates.
Machine learning direction
The first modeling objective is intentionally modest: estimate tonight’s sleep quality using today’s face image and same day activity metrics. Because sleep is recorded the following day, labels are shifted back one day to maintain temporal integrity.
Initial models prioritize stability and interpretability over raw predictive accuracy. Feature importance, correlation strength, and consistency across months matter more than short term performance.
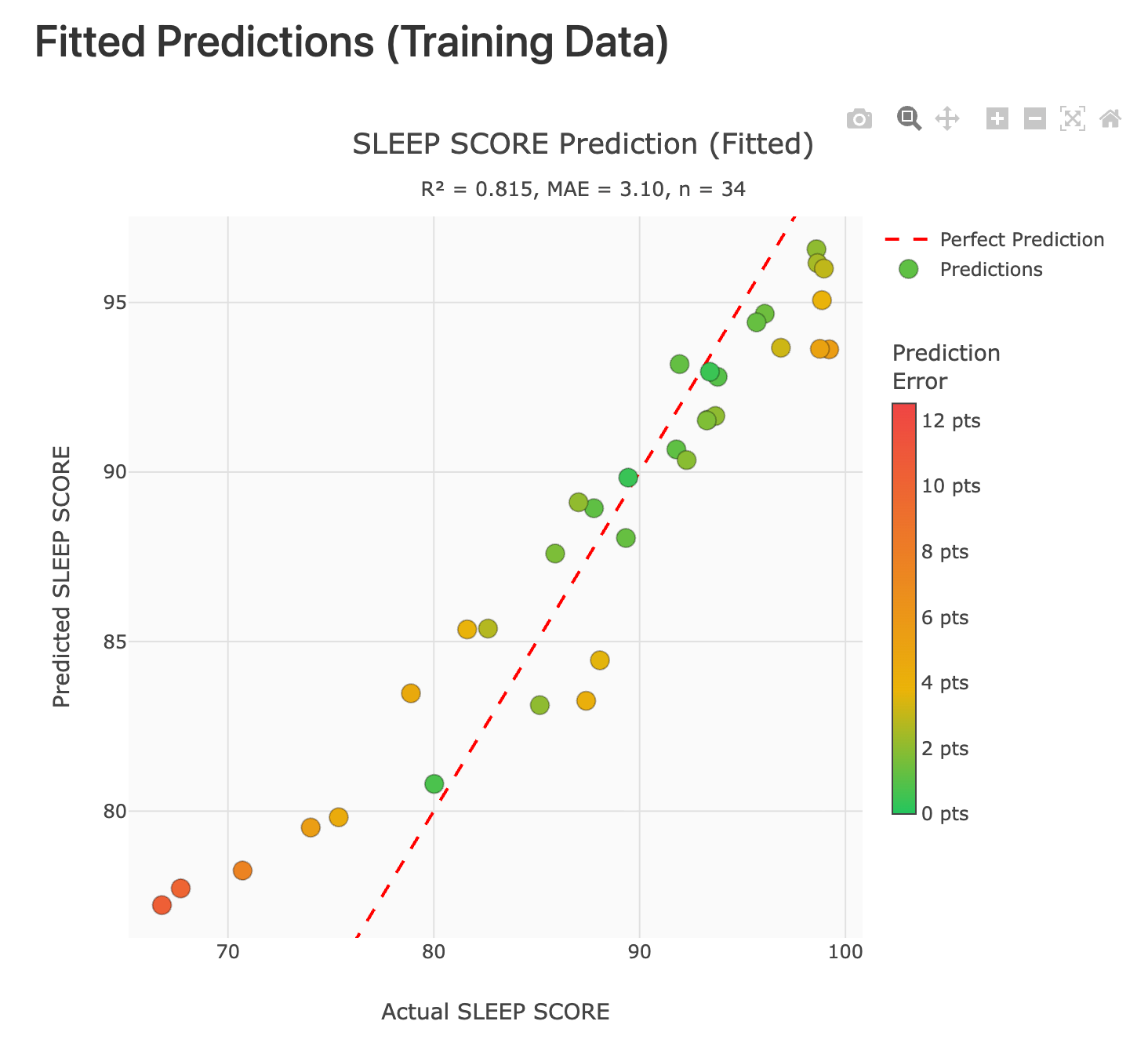
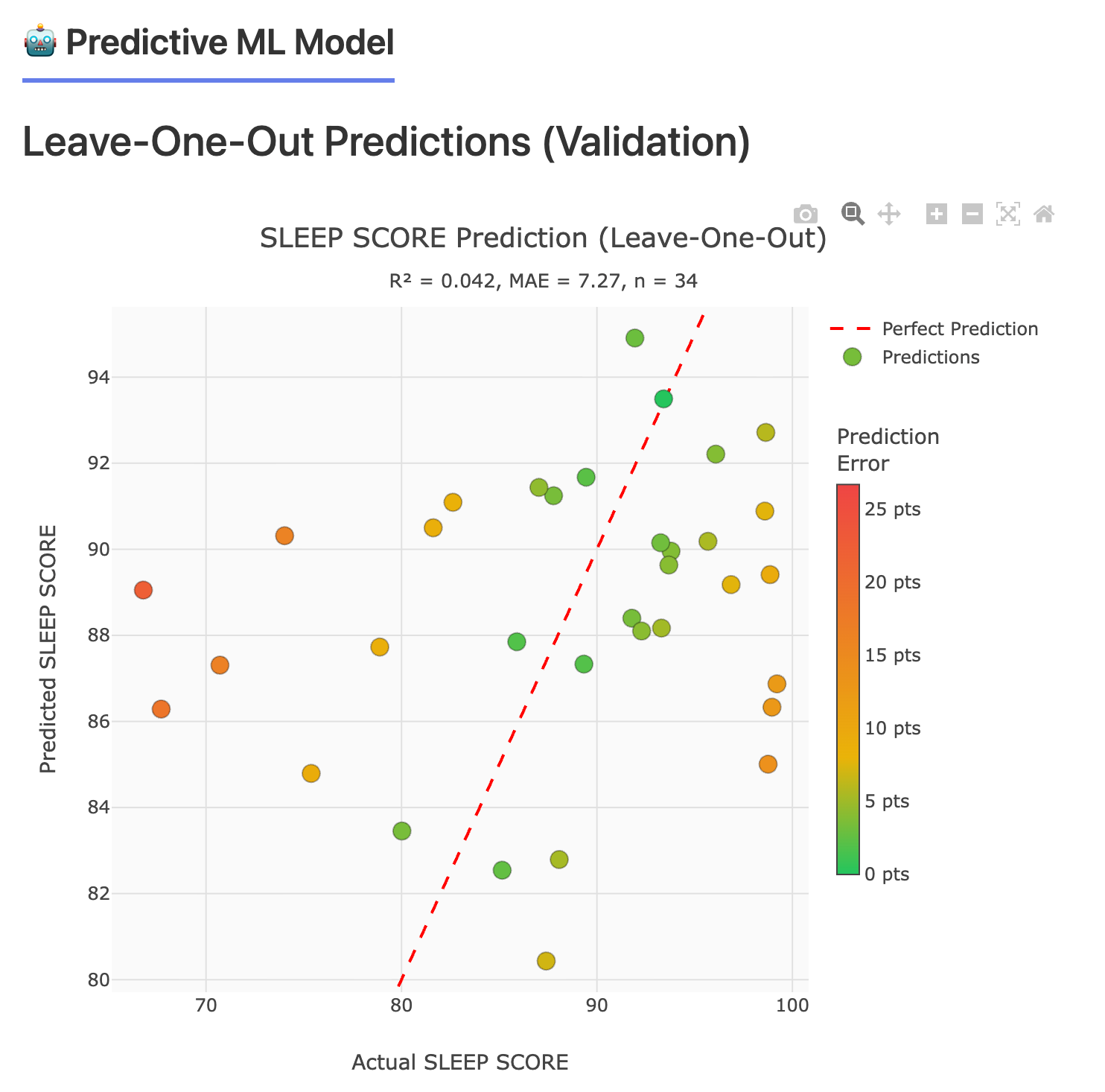
VERY Early Modeling Results: Training Fit vs Generalization
The two plots below illustrate an important principle that shows up in every data-driven system, especially when the dataset is still small: it is easy to learn the training examples, and much harder to generalize to new days.
In the fitted training plot, the model tracks the observed sleep score closely, with R² = 0.815 and MAE = 3.10. That looks encouraging, but it is also exactly where overfitting can hide: the model can appear strong simply because it has effectively memorized the patterns present in the examples it has already seen.
The leave-one-out validation plot is the first pass at answering the only question that really matters at this stage: does the model extrapolate? Here, performance drops sharply, with R² = 0.042 and MAE = 7.27, which is a clear signal that the current feature set, sample size, or both are not yet sufficient for reliable day-to-day prediction.
This is expected right now. Face → Health was implemented recently (literally on the day of this post!), and the current results are based on a small amount of legacy data. As new daily face captures accumulate in a consistent, time-aligned way, we expect both model stability and validation performance to improve. The immediate goal is not a high score on day one. The goal is to build a defensible pipeline that rewards generalization, not memorization, and to use validation methods like leave-one-out to keep us honest as the dataset grows.
A second track is exploring bidirectional correlations between facial embeddings and physiological metrics such as HRV, VO2 max, and recovery trends. Outputs are ranked correlates and metric specific reports, not black box scores.
Correlation is always reported as correlation. Causation is never implied.
Why this matters
Face to Health is not a novelty use of computer vision. It is a closed loop wellness system that learns from real personal data, enforces temporal correctness, and compounds in value over time.
It transforms a daily photo into a structured, queryable health signal. Over years, that signal becomes a form of memory: not of what happened on a single day, but of how patterns emerge, stabilize, and change.
Data Availability and Next Steps
To support longitudinal data collection going forward, I have built a small companion app that enables export of Apple Health data alongside daily face imagery in a consistent, time-aligned format. The app is currently in review in the Apple App Store. Once it is approved and publicly available, I will update the download link here:

This tooling matters because model quality in Face → Health is fundamentally data-limited right now, not architecture-limited. As more daily observations accumulate with consistent capture and clean temporal alignment, both feature learning and validation performance should improve in a principled way.
VI. System-Author Symbiosis: The Feedback Loop
This is where it gets philosophically interesting.
AI Steve is not only a tool I use. It has become a cognitive extension. The system has internalized decades of my reasoning patterns and reflects them back in ways that surface blind spots, resurrect forgotten context, and make long term patterns visible.
Four feedback loops
Knowledge amplification
Mechanism: decades of neural network expertise embedded in prompts and validation constraints
Example: evidence first rules, explicit uncertainty, and strict language around correlation
Memory consolidation
Mechanism: temporal reflection that aligns information across years
Example: this time last year comparisons that highlight how thinking evolves
Reasoning pattern mirroring
Mechanism: evidence forward response style shaped by my own writing
Example: quoting specifics and citing sources as default behavior
Legacy preservation
Mechanism: high priority weighting for family context and long horizon meaning
Example: the origin story of AI Dad remains central, because it is the seed of everything that followed
The Meta-Narrative: AI Documenting AI
The most direct demonstration of this symbiosis is the existence of this post.
AI Steve is now sophisticated enough to describe itself and help document its own architecture. It did not write this post as an autonomous author. Instead, it augmented the writing process by retrieving technical details from documentation, surfacing timeline events I would have otherwise missed, suggesting structure based on previous posts, and validating technical statements against the underlying code and system behavior.
I provide the narrative arc and the thematic framing. AI Steve provides recall, precision, and structural scaffolding.
VII. From AI-Dad to AI-Steve: The Evolution
It is worth tracing the arc from memorial to daily cognitive system.
Stage 1: grief driven innovation (early 2025)
Trigger: my father’s passing
Goal: preserve intellectual legacy through AI Dad
Approach: a RAG system trained on tens of thousands of content items, including emails, documents, and conversational Q and A
Stage 2: proof of concept
Achievement: conversational reconstruction of key reasoning patterns
Result: the system could answer legal questions, surface relevant context, and retrieve forgotten conversations
Learning: RAG plus temporal awareness can produce functional memorial intelligence
Stage 3: expansion to AI Steve
Insight: if this works for preserving Dad’s legacy, it should work for amplifying my own workflow
Features added: Code Directives, health monitoring, multimodal retrieval, face clustering
Use case shift: memorial system to daily cognitive assistant
Stage 4: self aware documentation (current)
Capability: the system supports accurate documentation of its own architecture and impact
Demonstration: this post
This evolution mirrors the transition from memorial artifact to daily cognitive system.
Future direction: AI assisted research, writing, and structured legacy curation at scale
The Broader Context: Grief Tech and Digital Legacies
AI Dad and AI Steve sit within a broader movement sometimes described as grief tech: systems designed to preserve and reconstruct aspects of deceased loved ones. Projects such as Muhammad Aurangzeb Ahmad’s Grandpabot, James Vlahos’s Dadbot, and Rebecca Nolan’s recreation of her father explore similar territory.
What makes AI Steve distinct is not that it is the first of its kind. It is that it is built as a dual purpose system: a memorial origin that evolved into a daily production workflow, with full domain integration, defensive engineering, and meta awareness strong enough to assist in documenting itself.
VIII. The Engineering Philosophy: Scientific Rigor Meets Personal Data
If there is a single throughline from my 1991 thesis to AI Steve in 2026, it is this:
Validate everything. Trust data over intuition. Acknowledge uncertainty. Iterate based on feedback.
That philosophy shows up everywhere:
When you spend decades validating model predictions against experimental ground truth, you develop a healthy skepticism of models. You learn to distrust confident outputs without evidence, quantify uncertainty, be explicit about limitations and assumptions, and iterate based on empirical feedback rather than elegance.
AI Steve embodies that discipline. It admits when it does not know. It quantifies correlation. It flags counterintuitive findings. This is what decades of neural network practice look like when applied to personal AI.
IX. The Future: Where Does This Go?
AI Steve is currently at version 4.5.13 and runs in production as part of my daily workflow. The roadmap ahead is ambitious.
This is not science fiction. It is a direct extension of what AI Steve already does: retrieve, align, synthesize, and enforce evidence.
The ethical dimension: who owns your digital self?
As personal AI systems become more capable, questions of identity, ownership, and privacy become unavoidable.
If AI Steve captures my reasoning patterns, who controls it after I am gone?
Should my daughters inherit access to AI Steve, and if so, under what rules?
What are the consent implications of training a system on decades of emails from other people?
How do we balance preservation of intellectual legacy with privacy and boundaries?
These are not abstract questions. They are the practical constraints of building an AI system around a real human life.
X. Conclusion: The AI That Knows You Better Than You Know Yourself
AI Steve started as a memorial project, a way to preserve my father’s intellect after his passing. It became a mirror of my own cognition, capable of surfacing blind spots, forgotten insights, and long term patterns I could not easily see on my own.
The system does not replace my thinking. It amplifies it.
By internalizing decades of my reasoning patterns, AI Steve has become an extension of intellect rather than a tool I occasionally consult.
The core paradox is unavoidable: the more AI Steve learns from me, the more useful it becomes. The more useful it becomes, the more I rely on it. The more I rely on it, the more it influences how I think. That is the feedback loop. Human and machine reasoning intertwined.
This is the future of personal AI: not generic chatbots that answer questions, but cognitive extensions that preserve, amplify, and evolve intellectual legacies. Systems trained on decades of our own data, reflecting our reasoning patterns back at us with a clarity we rarely achieve alone.
I started with neural networks predicting protein structures in 1991. Thirty five years later, I am using neural networks to predict my own context: surfacing what I knew but forgot, connecting dots I did not see, and preserving a legacy that can outlast me.
That is the symmetry.
The AI that helps me understand myself.
About the Author: Dr. Steven Muskal is CEO and founder of Eidogen Sertanty, with more than four decades of experience in AI driven drug discovery. He holds a Ph.D. in Chemistry from UC Berkeley (1991), where his thesis focused on neural networks for protein structure prediction. AI Steve is a personal project combining expertise in computational biology, machine learning, and knowledge management.
Technical details
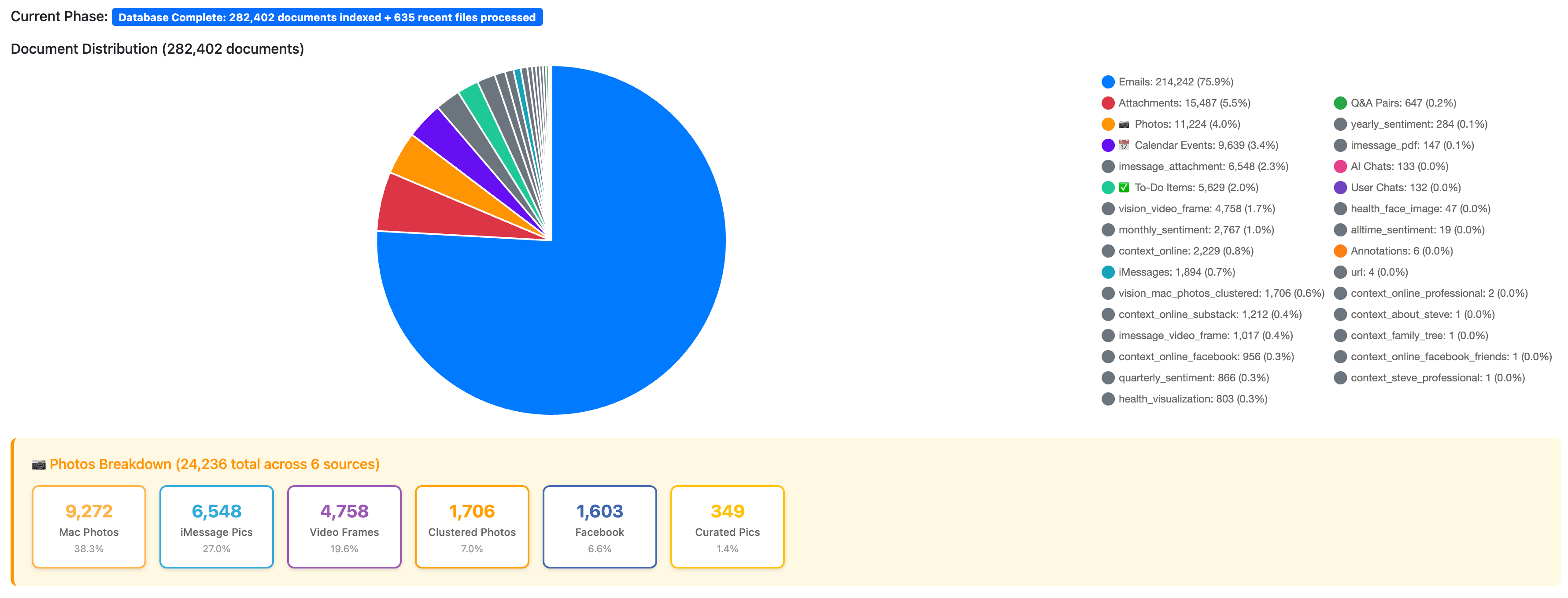
AI Steve is built on PostgreSQL with the pgvector extension. It uses OpenAI embeddings (text embedding 3 small) and Anthropic Claude Sonnet 4.5 for generation. The system processes more than 314,000 documents across 15 content types, with approximately 500 ms search latency and full temporal awareness.
Source code
AI Steve is a personal project and is not yet open source. The architectural principles and design patterns discussed here are broadly applicable to RAG based personal AI systems.
If you are interested in AI assisted legacy preservation, computational biology, or the intersection of personal knowledge management and machine learning, drop me a line and/or follow my Substack for updates.
AI Steve assisted: January 30, 2026
System version: AI Steve 4.5.13
Steve

Steven Muskal, Ph.D. is the CEO of Eidogen-Sertanty, Inc. — a drug discovery informatics company. He has spent four decades working at the intersection of computational biology, AI, and drug discovery. He writes about AI, health, and the intersection of biology and technology at stevenmuskal.com
For a few samples from a recent mix - a few blasts from the past, first time for most, even a fade-out on She’s Not There! RickL (Vocals), TimD (Guitar/Volcals), GeoffS (Bass/Vocals)
Couldn't agree more; your insight into personal AI as cognitive mirors is profound, making me wonder if they also amplify empathy.
Exceptional work on encoding scientific rigor into system behavior. The seven anti-hallucination rules aren't just prompt engineering, they're decades of validation discipline translated into executable constraints. I've seen too many RAG systems that hallucinate confidently because nobody bothered to build feedback loops or uncertainty quatification into the architecture. The leap from protien structure validation in '91 to personal AI in '26 is actually a straighter line than most people realize.