

The N-of-1 Health Stack
Why personal data, not population averages, should drive health insight


I’ve been thinking a lot about why so much health data feels busy but not useful.
Most of us now generate an extraordinary amount of physiological data. Heart rate, sleep stages, movement, temperature, oxygen saturation, labs, workouts, recovery scores. Apple Health alone quietly accumulates thousands of data points per year.
And yet, for all that measurement, very little of it actually compounds into understanding.
Dashboards refresh. Scores fluctuate. Trends come and go. But insight rarely deepens.
That gap has been bothering me, and it’s what led me to start working on what I’m calling the N-of-1 health stack.
The hidden assumption behind most health analytics
Most health systems are built on an unspoken assumption: that population averages are the right reference frame.
They ask questions like:
How do you compare to people your age?
Are you above or below the mean?
Are you inside a “normal” range?
Those questions are useful in clinical screening contexts. They are much less useful for understanding how a specific human system behaves over time.
Two people can sit at the same population percentile while moving in completely different directions physiologically. One may be adapting well. The other may be quietly degrading. Population statistics are designed to smooth variance, but variance is often where the most important signals live.
Health data framed this way become descriptive rather than explanatory. It tells you where you are relative to others, not how you change in response to stress, sleep, diet, illness, or habit.
Why N-of-1 changes the question
An N-of-1 approach flips the reference frame.
Instead of asking,
“How do I compare to everyone else?”
It asks:
What is normal for me?
How stable is that baseline?
What changes when I change something?
Which signals move first, and which follow?
In this framing, the individual becomes their own control. Time becomes a first-class variable. Repeated exposures matter more than isolated measurements.
The goal isn’t diagnosis.
It’s understanding trajectories.
From tracking data to building a stack
Most people are tracking health data.
Very few are building a health stack.
Tracking answers the question:
“What’s happening right now?”
A stack answers the question:
“What compounds over time?”
For me, a health stack has a few essential layers:
Data ownership
Raw, exportable, user-controlled data rather than locked dashboards.
Continuity
Longitudinal records that persist across devices, years, and vendors.
Alignment
Signals from different domains synchronized in time.
Interpretability
Representations that can be reasoned about, not just scored.
Extrapolation
Models that generalize beyond the data they were trained on.
This is where Apple Health becomes interesting, but only if the data can actually leave the phone.
Why exporting Apple Health matters
Apple Health is one of the richest personal health repositories available today. It aggregates data across sensors, contexts, and time. But most of that richness is locked behind dashboards and summaries.
Dashboards are motivational.
They are not cumulative.
The real value of Apple Health emerges when the raw data can be exported, aligned, and reasoned about over long time spans.
I’ve been working on tooling that enables:
Structured export of Apple Health data
Alignment of heterogeneous signals across time
Optional inclusion of face imagery for exploratory analysis
This is infrastructure, not a polished product.
Very early days.
Early experiments: face and health
As an initial exploratory step, I’ve started looking at relationships between facial features and health signals.
To be clear about scope:
The datasets are small AND growing
The results are preliminary
The intent is methodological
While it is unclear if faces can “predict” health, it sure would be interesting AND useful if your external facial features might correlate with your internals.... Wouldn’t it be nice if one day a simple selfie (or a facial phone unlock) might one day act as a surrogate to a blood draw? Who knows, one day your phone, might offer a positive nudge or provide a suggestion or two as you embark on each new day. Surely this would be a lot more useful than doom scrolling…
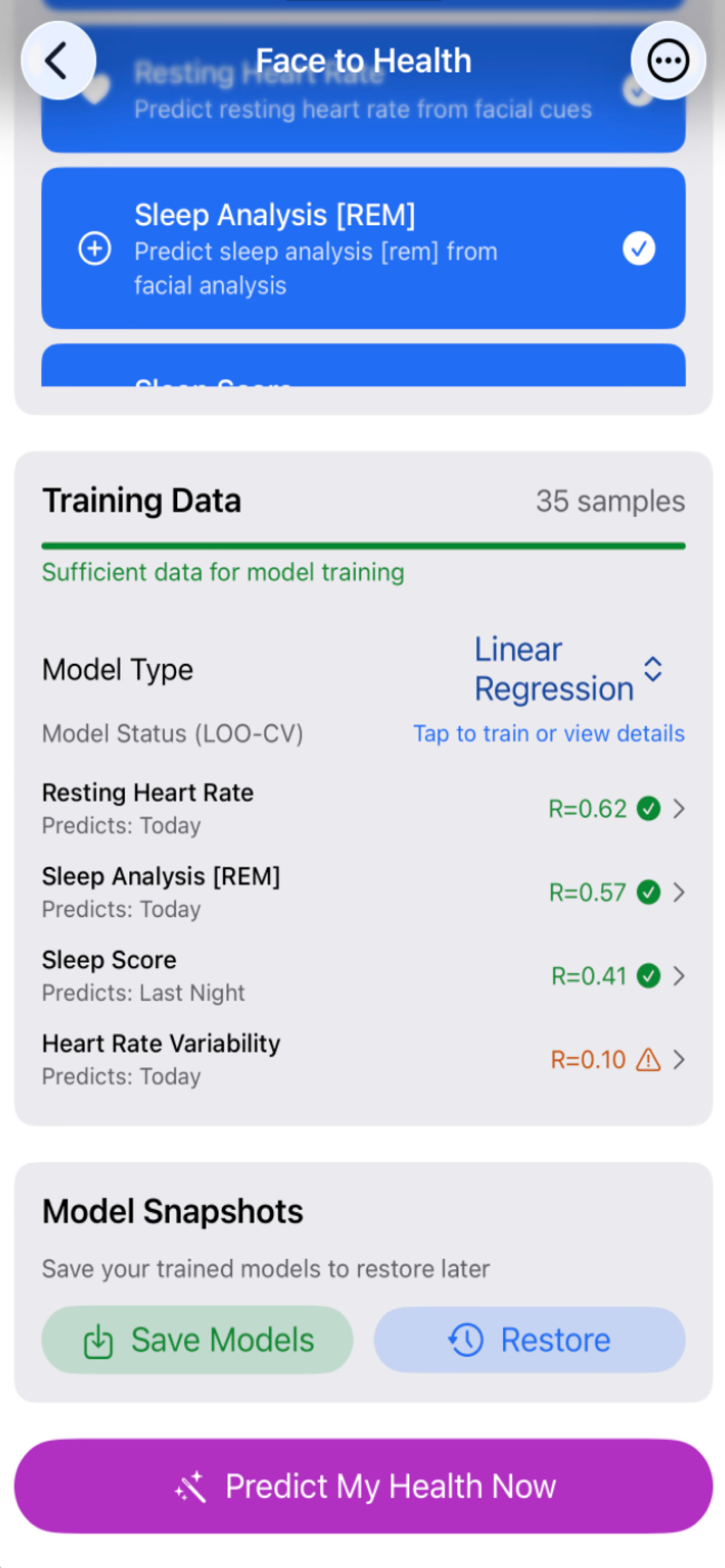
The figures below are meant to illustrate structure and direction, not conclusions.
Overfitting, extrapolation, and why evaluation matters
One of the easiest mistakes to make in personal health modeling is overfitting.
With enough parameters, almost any dataset can be fit extremely well. That doesn’t mean anything meaningful has been learned.
Accuracy on training data is not insight.
Generalization is.
As a first pass at guarding against this, I’ve been using simple leave-one-out style evaluations. Each day of data is removed in turn, the model is refit, and stability is assessed.
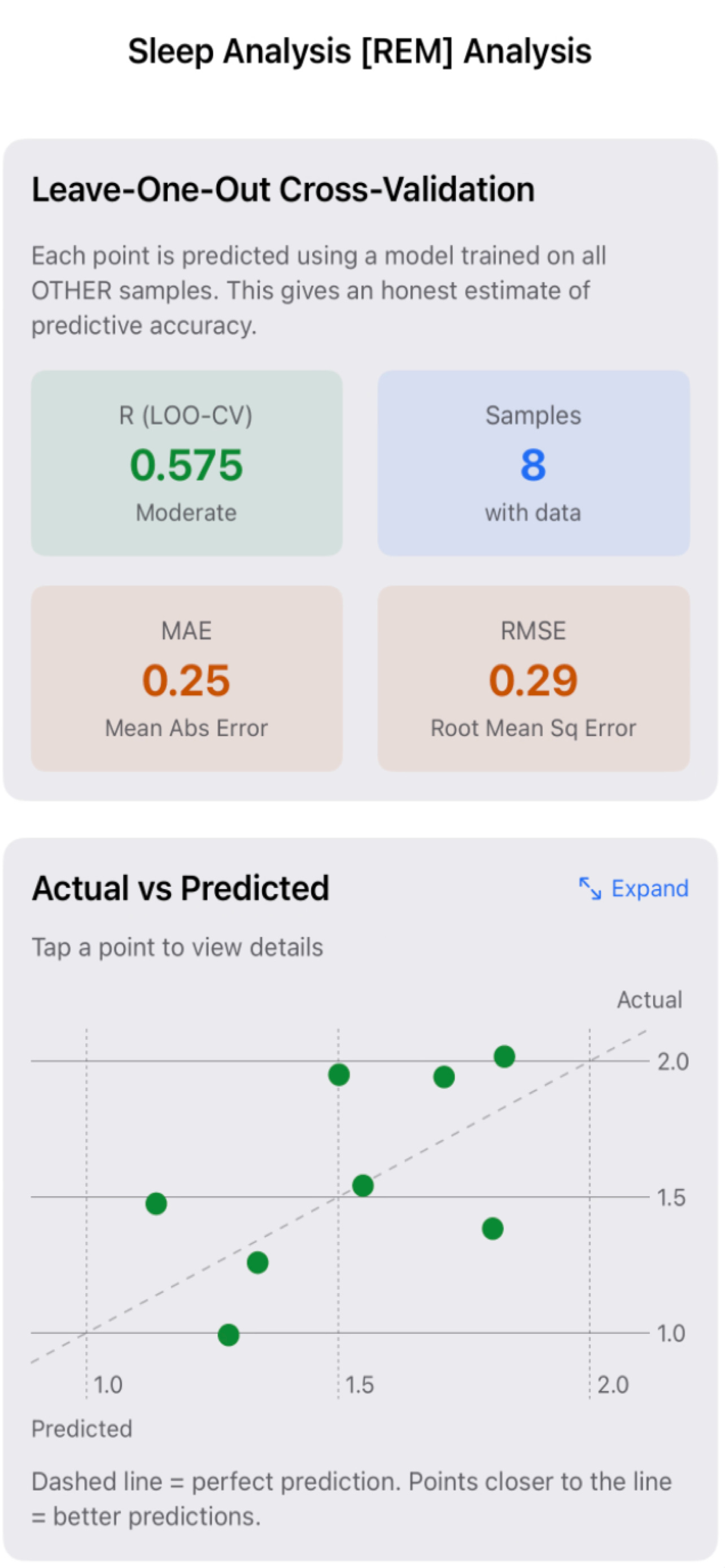
The question is not “How good is the fit?”
It’s “Does the structure survive removal?”
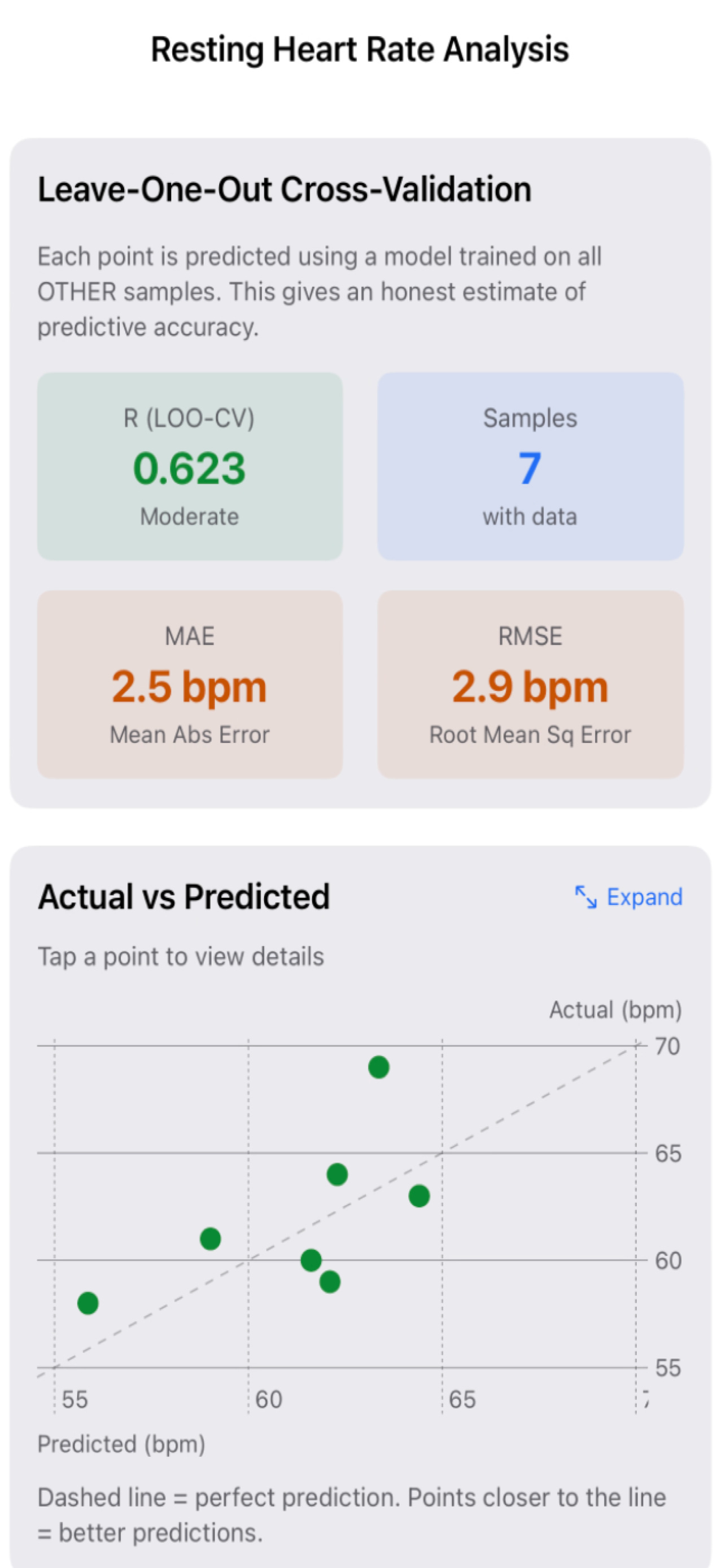
If a relationship collapses when a single point is removed, it’s not insight. It’s curve fitting.
What this is and what it is not
This work is not medical advice.
It is not diagnostic.
It is not intended to replace clinical judgment.
It is about personal signal discovery.
About learning how your own system behaves across time, stressors, habits, and interventions.
Think less:
“What does this number mean?”
Think more:
“What changes when I change something?”
Where this is going
Right now, the focus is on foundations:
Reliable data export
Structural alignment
Exploratory visualization
Training set build-up
Guarding against overfitting
Next comes:
Larger longitudinal datasets
More rigorous extrapolative evaluation
Personal baselines that evolve over time
Models that capture directionality rather than static thresholds
Eventually, this moves toward something closer to personal health reasoning, where data compounds instead of resetting every day.
Closing thought
Health data are abundant. Insight is rare.
The limiting factor isn’t sensors or algorithms.
It’s perspective.
Health data matter only when they are grounded in how individuals change over time, not in how they compare to everyone else.
That’s the promise of the N-of-1 health stack.
ShareHealth is one instantiation of that idea, but the principle applies far beyond any single tool.
Source code for Share Health (GitHub)

Steven Muskal, Ph.D. is the CEO of Eidogen-Sertanty, Inc. — a drug discovery informatics company. He has spent four decades working at the intersection of computational biology, AI, and drug discovery. He writes about AI, health, and the intersection of biology and technology at stevenmuskal.com
For a “raw” mix sample, another from my recent B-Day mix a couple months back. Some of my favorites - Tammy (vocals) leading, Maya (vocals/acoustic) assisting, Grant (guitar), Dom (Guitar) and Alan (Bass) driving.