

Universities Built the Bomb. Now Build This.
The Knowledge Arms Race Has Already Started

By Steven Muskal, Ph.D. | The Renaissance Circle | June 26, 2026 | stevenmuskal.com
The Conversation That Started This
, UC Berkeley")
Earlier this week I zoomed with my graduate research advisor and mentor Sung-Hou Kim (age 88). We discussed many things, including where things are heading for research universities. We have become reacquainted after 35 years and have had a couple calls prior to a planned reunion on the Berkeley campus a few weeks from now (August 1, 2026). Sung-Hou groomed many thought leaders over the years. I am especially looking forward to meet for the first time during this star-studded alumni gathering the legendary Harvard geneticist George Church, famed structural biologist Joel Sussman, and a whole cast of thought leaders who have worked in the Kim lab over the years. Sung-Hou and I were discussing AI and agreed: people who embrace AI will increasingly outperform those who refuse to use it. The question that followed naturally was whether the same dynamic applies to institutions. If individual experts can be passed by the tool, so can universities. The open question is whether they will see it coming in time to do something about it.
I have been thinking about that conversation ever since. This essay is where I landed.
The Innovator’s Dilemma
Clayton Christensen described the trap in 1997. A successful organization encounters a disruptive new technology and hesitates to adopt it, because the new thing threatens the very business model that has made the old thing successful. The hesitation is not irrational. It is rational self-preservation. The new model looks small and unproven. The existing model is still generating revenue. From the inside, killing the golden goose feels reckless.
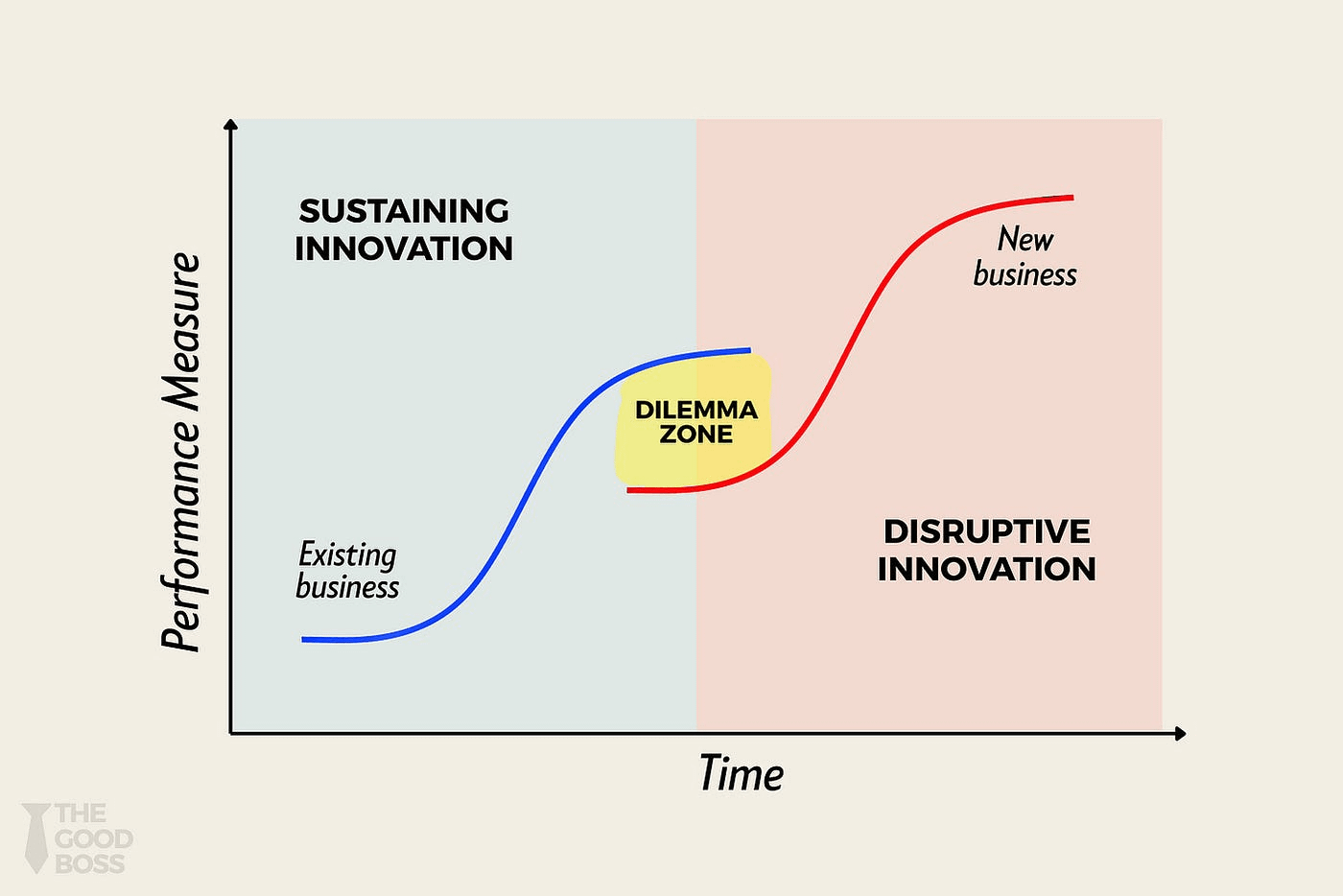
Universities fit this description almost perfectly. The brand of a Harvard, a Stanford, a UC Berkeley is tied directly to scarcity: limited seats, selective admissions, a residential experience that costs 5-to-6 figures per year. The implicit promise is that proximity to world-class faculty and peers is something you cannot get anywhere else. Any model that genuinely democratizes access to that knowledge runs the risk, from the institution’s perspective, of diluting exactly what makes the degree valuable.
That logic is understandable. It is also, I believe, wrong. And we have already run the experiment that demonstrates it.
The Online-Education Precedent
In 2012, Harvard and MIT launched edX. That same year, Andrew Ng and Daphne Koller, both Stanford faculty, co-founded Coursera. The prediction from those who defended the traditional model was that putting lectures online would erode the value of an on-campus degree. That prediction was wrong.

edX grew to tens of millions of learners across more than 160 countries without any perceptible reduction in the prestige of a Harvard diploma. Coursera raised over a billion dollars in venture funding and went public in 2021. Georgia Tech launched an online master’s degree in computer science for under $7,000, now one of the largest graduate CS programs in the world, and its residential programs have lost none of their standing. The schools that leaned into online education discovered that access and prestige are not enemies. They widened their reach, opened new revenue streams, and their brands emerged stronger, not weaker.
The lesson is not that online education is identical to the residential experience. It is not. The lesson is that the university’s accumulated knowledge is far more durable and far more transferable than the institution’s defenders feared.
The Concrete Proposal
The next logical step goes further than streamed lectures. Every serious research university sits on something extraordinary: decades of published research, course syllabi, lecture recordings, library collections running to millions of volumes, and the accumulated working knowledge of its faculty, postdocs, scientists, and staff. That corpus is alive and growing. It is not static, and it is not generic. It is exactly the kind of high-quality, specialized content that makes a powerful language model genuinely useful rather than confidently wrong.
Imagine a university-specific large language model, trained and retrieval-grounded on that corpus. Not a chatbot that has absorbed the entire internet and then hallucinated its way through the gaps. A focused, institution-specific system that knows Berkeley chemistry the way Berkeley chemists know it, that can trace every answer back to a specific paper, a specific lab, a specific course. Offered as subscription access, it extends the university’s mission to anyone in the world with curiosity and a connection, without a single diploma being devalued.
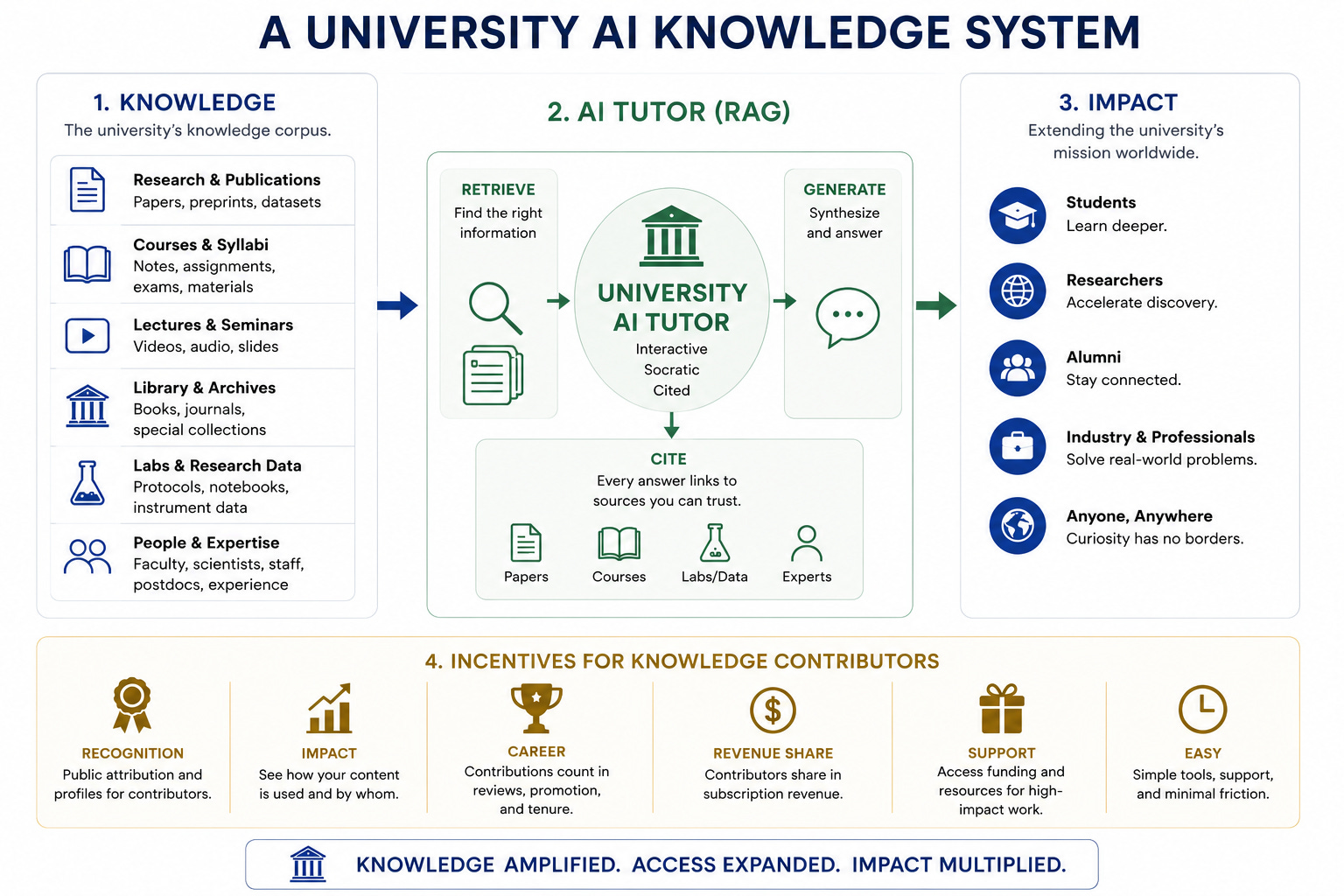
The interface matters as much as the corpus. Static video lectures, however beautifully produced, put the learner in the role of spectator. Interactive question-and-answer dialogue puts them in the role of student. The difference between watching a surgery and being trained to perform one. At its best, the AI interface is Socratic: it meets the learner where they are, follows their questions, asks what they already understand, and calibrates accordingly.
The Hard Parts, Handled Honestly
I do not want to oversell this. The engineering and the policy challenges are both real.
Accuracy and hallucination. Language models are statistically fluent and factually unreliable when they venture outside their verified training data. The standard mitigation is retrieval-augmented generation: the system retrieves passages from the institutional corpus before answering, and grounds its response in those passages. It is not a complete solution, but it shifts the failure rate in the right direction and, critically, makes errors auditable. A citation back to a specific document is something a user can check and an institution can stand behind.
There is a deeper point here that deserves emphasis. Many of the factual failures we associate with today’s large language models begin with the quality of the knowledge they consume. Most frontier models have been trained on vast swaths of the open internet, a corpus that includes misinformation, contradictions, outdated claims, low-quality content, and increasingly, text generated by other language models. Their statistical understanding inevitably reflects both the strengths and the weaknesses of that data.
University and college collections are fundamentally different. Published research has survived peer review and editorial scrutiny. Course materials have been developed and refined over years of teaching and student feedback. Library collections have been curated by professional librarians, while faculty lectures and departmental resources reflect the collective expertise of recognized scholars. No corpus is perfect, but it is vastly more authoritative, internally consistent, and accountable than the open web.
A language model grounded in this corpus does more than retrieve better answers. It reasons from higher-quality evidence. Combined with retrieval-augmented generation and citation back to original sources, this creates a structural advantage: factual claims become verifiable, errors become auditable, and the model is far less likely to drift into unsupported assertions. Rather than trying to correct hallucinations after they occur, the system reduces them by grounding its responses in one of the highest-quality knowledge repositories humanity has assembled.
Citation and provenance. Every answer should link to its source: the paper, the textbook chapter, the lecture segment. Not only because academic culture demands attribution, but because it lets the learner verify the claim and go deeper. This is achievable with current technology. It requires disciplined indexing of the corpus and careful system design, but it is not a research problem; it is an engineering one.
Licensing of scholarly content. This is the thorniest problem. Universities publish research through journals that may retain copyright. Course materials may carry layered IP ownership across instructors, departments, and the institution itself. Open-access publishing helps, but it does not solve the problem entirely. A serious deployment requires legal review, negotiated rights, and in some cases revenue sharing with rights holders. This is an argument for starting deliberately, not an argument against starting.
Privacy. Student records, researcher correspondence, health data, and unpublished work have no place in any training corpus or retrieval index. The boundary between what is public-facing and what is not must be designed in from the beginning, with the same rigor a hospital applies to patient data. This is non-negotiable, and it is also clearly achievable.
Faculty incentives, credit, and compensation. A professor’s lectures, papers, and course materials represent years of concentrated effort. Any system that ingests that work should credit it and, in a subscription revenue model, share the returns with the faculty who generated it. This is both fair and strategically necessary: faculty buy-in determines the quality of the corpus, and buy-in follows fair treatment. The revenue-sharing framework already exists in other knowledge industries; universities are capable of inventing their own version.
Why Berkeley Should Lead

If there is one institution that should recognize this moment for what it is, it is UC Berkeley.
In Room 307 of Gilman Hall, during the winter of 1940 to 1941, a young chemist named Glenn Seaborg and his colleagues bombarded uranium-238 with deuterons and, on December 14, 1940, first produced plutonium-239. By February 1941 they had chemically separated and conclusively identified element 94, the first isolation of plutonium in history. That room is now a National Historic Landmark, recognized not because the chemistry was elegant but because the discovery changed what the world was capable of.

The material that Seaborg identified came from the cyclotron that Ernest Orlando Lawrence had built just up the hill. Lawrence started in 1930 with a machine four and a half inches across, housed in a wooden shack on the Berkeley campus. By 1939 he had scaled to a 60-inch instrument powerful enough to earn him the Nobel Prize in Physics. The institution he founded became Lawrence Berkeley National Laboratory, a national resource that has operated continuously for more than eighty years and has produced thirteen Nobel laureates among its researchers.

And it was at Berkeley that J. Robert Oppenheimer spent fourteen years as a physics professor, from 1929 to 1943, building one of the great theoretical physics programs in the world. The summer conference he organized at Berkeley in 1942, gathering some of the century’s most consequential minds in physics, became the theoretical seed of Los Alamos. Berkeley did not merely participate in the next chapter of history. It convened it.
I recently came across the passage below as the opening epigraph of The Infinity Machine: Demis Hassabis, DeepMind, and the Quest for Superintelligence. Von Neumann was describing the dawn of the nuclear age in 1945. Replace the phrase “energy source” with “intelligence source,” and the passage could have been written yesterday.


In each case, the pattern was the same. The institution did not stand at a distance and observe a powerful new capability emerging. It organized around it, funded it, gathered the talent, and built infrastructure that outlasted any individual contribution. The cyclotron became the national laboratory. The chemistry became the periodic table extended. The physics conversations became the project that ended a world war.
Berkeley knows, in its institutional memory, what it means to carry powerful fire. The question is whether it and the universities that share its ambitions will recognize the current moment as belonging to the same tradition.
A Call to Action
I want to speak directly to university leadership for a moment, because the frame matters.
The wrong frame is: how do we protect what we have? That frame leads to incremental gestures, a committee here, a pilot program there, a decision to wait until the landscape clarifies. The landscape is not going to clarify in the direction of patience. The institutions that build now will define what university knowledge systems look like for the next generation. The institutions that wait will buy access to systems that someone else built.
The right frame is: what can we build that no one else can build? No one else has Berkeley’s corpus. No one else has the combination of published research, teaching materials, library depth, and faculty expertise that a serious research university has accumulated over a century of operation. That corpus is the moat. It is not the name on the diploma; it is the accumulated knowledge behind it. The question is whether to keep that knowledge locked inside the campus walls or to let it reach anyone in the world who wants to learn from it.
I am not arguing for giving everything away for free. Subscription models work. Online professional certificates work. Revenue sharing with faculty works. The university does not have to choose between mission and margin. The path is to expand the mission, not to surrender it.
Institutions like Berkeley have a singular opportunity right now: to transform decades of published research, educational content, and faculty expertise into AI-accessible knowledge systems that reach far beyond the lecture hall. That is not cannibalization. That is multiplication.
In a piece I will publish soon - AI for Everyone (sneak peek below), I argue that the answer to fire was never to extinguish it. The answer was to learn how to carry it, to build hearths around it, to teach people how to use it safely and well. That same argument applies here, and it applies with urgency.
The fire is already lit. Berkeley helped light it. The question now is whether the university will help carry it forward, or stand at the gate and watch it pass by.
Sources and further reading
Glenn Seaborg on Gilman Hall Room 307, Lawrence Berkeley National Laboratory
Gilman Hall Room 307, National Park Service
Oppenheimer’s Berkeley Years, Berkeley News
The Innovator’s Dilemma, Clayton Christensen (1997)
AI for Everyone, sneak peek to a companion essay soon to appear

Steven Muskal, Ph.D. is the CEO of Eidogen-Sertanty, Inc. - a drug discovery informatics company. He has spent four decades working at the intersection of computational biology, AI, and drug discovery. He writes about AI, health, and the intersection of biology and technology at stevenmuskal.com