

We’ve Already Reached AGI. The Market Just Hasn’t Admitted It Yet.
The Zero to One moment already happened. What markets are pricing now is One to N.

If a system can replace high-skill human labor across domains, in real time, at global scale, what exactly are we waiting for before we call it Artificial General Intelligence (“AGI”)?
We are watching AI:
Write production software
Draft legal agreements
Generate investment memoranda
Synthesize scientific research
Diagnose patterns in medical data
Architect complex systems
Not in research labs. In production. The debate about AGI continues. But the definition keeps shifting.
If AGI means economically useful, cross-domain intelligence that rivals or exceeds the median human, we are already there. The more interesting question is this:
If AGI is already here in practical terms, why does the capital market behave as though we are still chasing it?
Zero to One Already Happened
Peter Thiel’s Zero to One draws a sharp distinction between invention and iteration.
Zero to One is a discontinuity. One to N is scaling.
The emergence of transformer-based systems capable of generalizing across language, reasoning, coding, planning, and synthesis was a Zero to One moment. Scaling them from GPT-3 to GPT-4 class systems and beyond is largely One to N.
More parameters.
More tokens.
Lower latency.
Better guardrails.
Important improvements. But incremental.
The breakthrough already occurred. Markets, however, are still pricing as if intelligence itself remains scarce.
The Cognitive Benchmark Problem
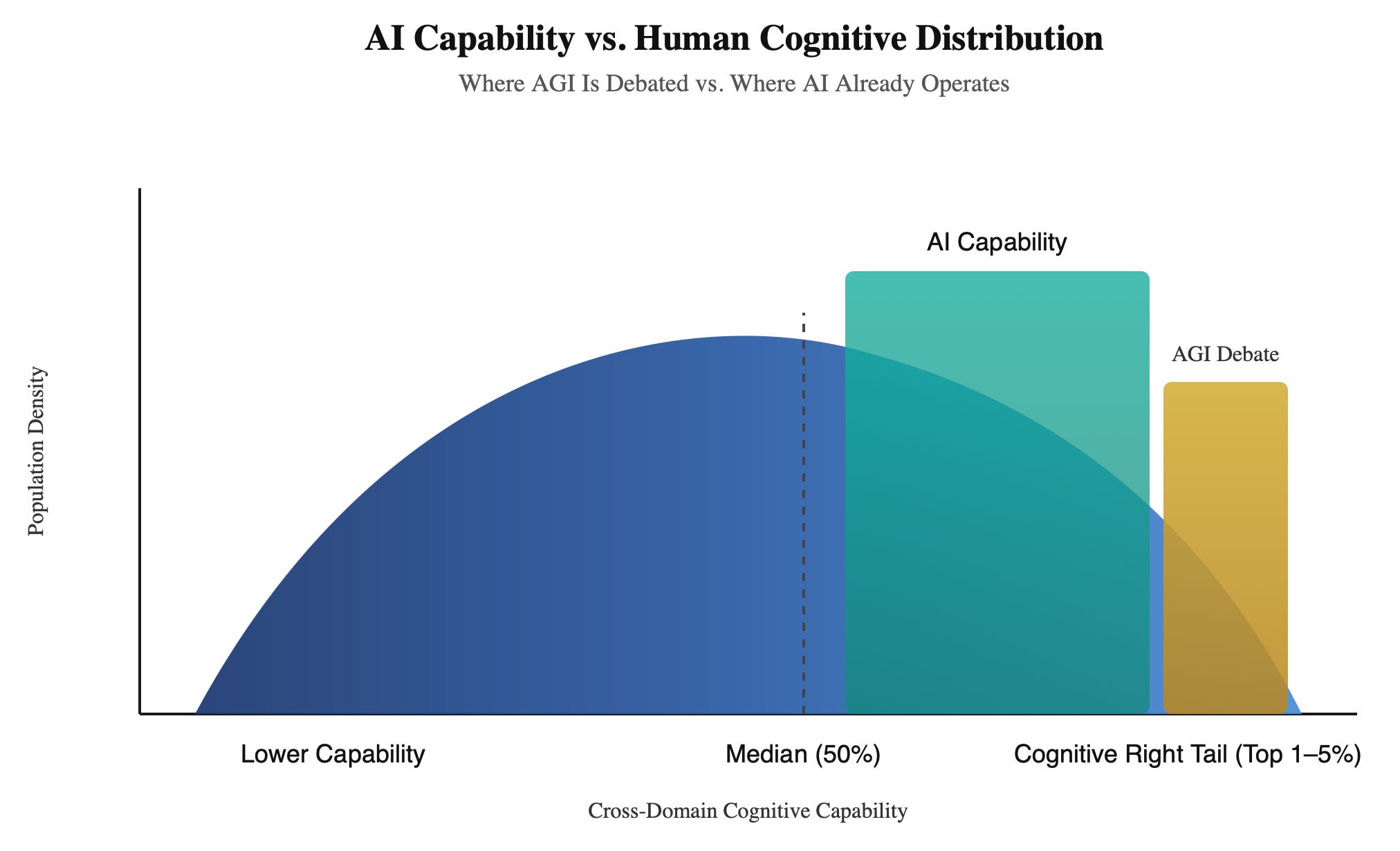
Most AGI debates occur among educated engineers, researchers, founders, and academics.
When they say human-level intelligence, they implicitly benchmark against:
Top engineers
Researchers
Founders
Highly literate professionals
Abstract thinkers
That is not the human median. That is the cognitive right tail.
According to the U.S. Department of Education’s National Assessment of Adult Literacy and analyses from the National Center for Education Statistics, roughly 54 percent of U.S. adults read below a sixth-grade level. Around 20 percent are functionally illiterate.
Zoom out to the full population distribution:
Many adults struggle with multi-step reasoning
Many cannot synthesize technical information
Many cannot write structured analytical prose
Very few can code
Very few can reason abstractly across domains
AI systems today exceed a massive portion of the human cognitive distribution.
If AGI means matching the top 1 percent of engineers across all domains, perhaps we are not there. If AGI means exceeding the median human across reasoning, writing, synthesis, and structured thought, that threshold has already been crossed.
The debate persists because the benchmark silently assumes the right tail and because the goal posts keep getting pushed back.
Once conversational fluency was achieved, the bar became reasoning purity.
Once reasoning improved, the bar became agency.
Once agency emerges, the bar becomes embodiment.
The definition recedes as soon as the prior threshold is cleared.
A Personal Perspective From the Long Arc

I began working with neural networks in the mid-1980s as an engineering student, when backpropagation was still debated and neural methods were widely dismissed as impractical.
My doctoral work at Berkeley focused on neural network methodology development for protein structure prediction. At the time, using neural networks to infer biological structure was viewed as ambitious and speculative. Even then, these systems exhibited an insatiable appetite for high-quality data, yet such data were scarce and difficult to obtain.
Fast forward three decades. The team behind AlphaFold was awarded the Nobel Prize in Chemistry for solving protein structure prediction at scale - powered, yes, by neural networks.
That arc matters.
What begins as fragile methodology becomes validated science.
What becomes validated science becomes industrialized.
What becomes industrialized becomes infrastructure.
We are watching the same arc unfold in general intelligence.
The conceptual barrier has already fallen. The remaining work is scale, optimization, and deployment.
Training Is Not Deployment
One of the most persistent misconceptions in the AGI and GPU debate is the conflation of training with deployment.
Training frontier models is computationally extreme. It requires massive GPU clusters, extraordinary energy consumption, and enormous capital expenditure.
That is where the largest chips and the most power-hungry data centers live.
But deployment is not training.
Deployment is inference.
And inference does not require the latest and greatest GPUs, nor constant retraining of ever-larger models on the entire corpus of world information, nor nuclear-scale power plants feeding hyperscale facilities.
Training discovers the weights.
Inference executes them.
Once weights are learned, economics change.
From Scale to Efficiency
After a model is trained, multiple techniques dramatically reduce its computational footprint:
Quantization reduces numerical precision, shrinking memory and compute requirements.
Distillation transfers knowledge from large models into smaller ones that preserve much of the capability at a fraction of the cost.
Pruning removes redundant parameters.
Sparse routing activates only portions of a network at a time.
Hardware-aware compilation optimizes execution for specific chips.
These are not speculative ideas. They are standard production techniques.
The result is that inference is far cheaper and less energy-intensive than training.
Intelligence can then be deployed on:
Low-power accelerators
Specialized silicon
Edge devices
Application-specific integrated circuits
Weights can even be embedded directly into silicon for fixed-function inference.
Training may remain centralized. Deployment does not have to be.
That distinction matters enormously for capital markets.
Nvidia’s Meteor Arc
Nvidia’s rise has been extraordinary.
Approximate market capitalizations:
1999 - ~1 billion
2010 - ~9 billion
2020 - ~300 billion
2023 - ~1.2 trillion
Late 2024 - ~3.3 trillion
Early 2026 - ~4.5 trillion
From 2020 to 2025 alone, Nvidia added more than 4 trillion dollars in market value.
At roughly 4.5 trillion dollars, Nvidia represents about 7 to 8 percent of the S&P 500, whose total market capitalization sits near 60 trillion dollars.
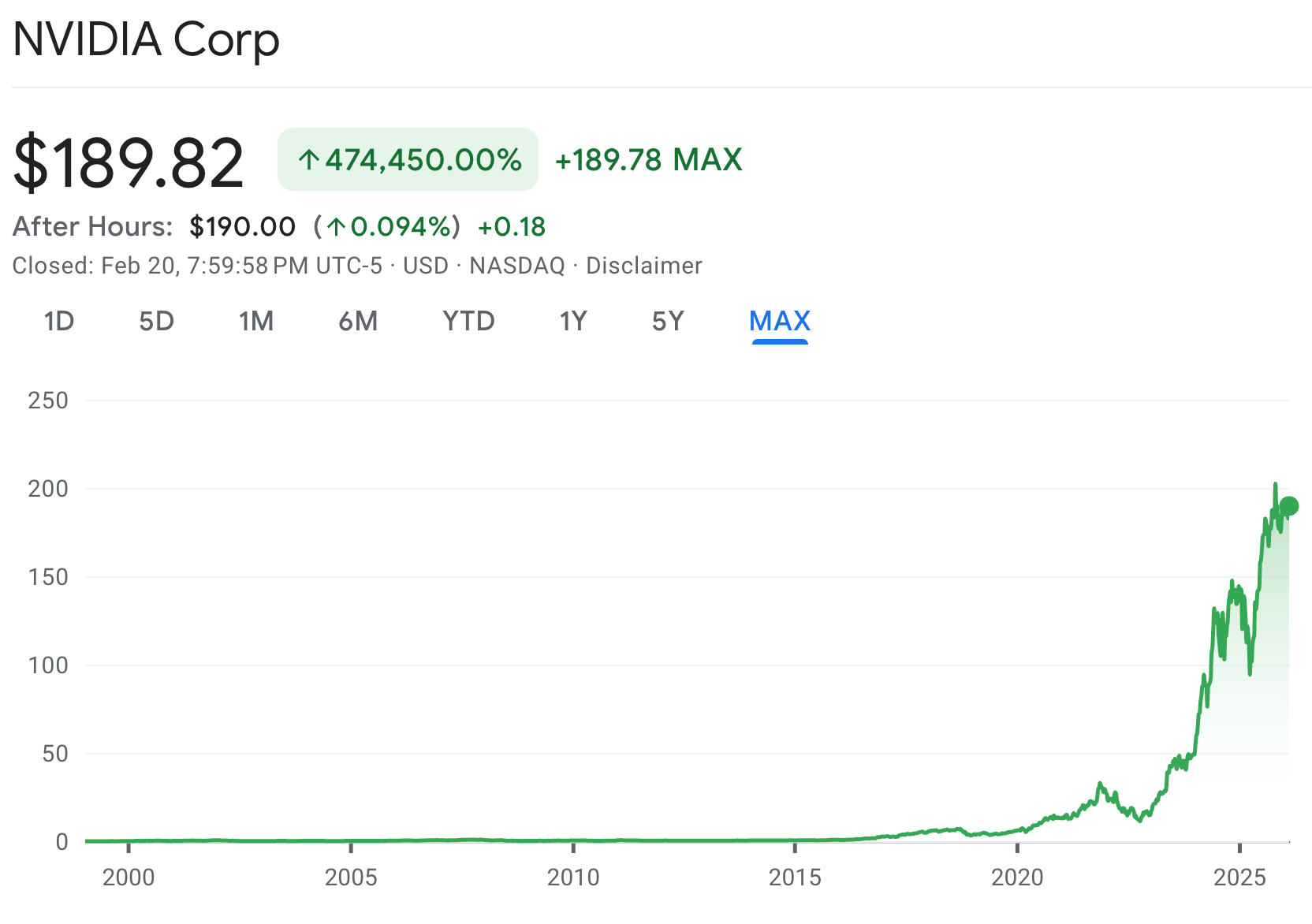
Figure 1. Nvidia Stock Price 1999 to 2026.
The concentration is historically rare. But the arithmetic weight understates the systemic exposure.
The S&P 500 Exposure Is Networked, Not Linear
Direct mechanical drag modeling:
Assume S&P 500 total market cap ≈ $60T (simple baseline).
Assume Nvidia market cap ≈ $4.621T (Feb 2026 snapshot).
That implies Nvidia weight ≈ 7.70 percent.
The direct, first-order index drag is: weight × Nvidia move.
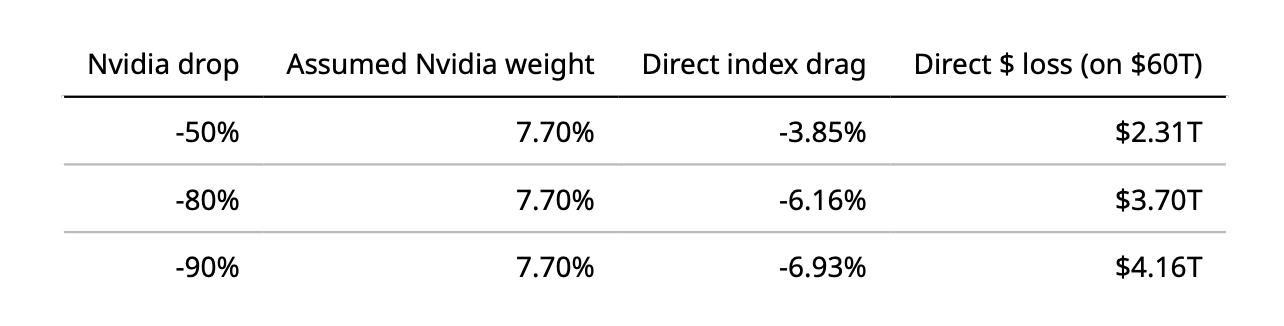
A simple mechanical model suggests:
A 50 percent Nvidia decline implies roughly a 3 to 4 percent S&P drag.
An 80 percent decline implies roughly a 6 percent drag.
A 90 percent decline implies roughly a 6 to 7 percent drag.
That math assumes independence.
Reality is different.
The largest S&P 500 companies are tightly coupled around AI infrastructure.

Microsoft depends on Nvidia GPUs for Azure AI services.
Amazon integrates Nvidia hardware deeply into AWS.
Alphabet and Meta invest tens of billions annually in AI data centers.
Apple’s AI roadmap depends on ecosystem compute partnerships.
Nvidia invests in AI startups.
Hyperscalers invest in companies that depend on Nvidia.
Index funds hold all of them simultaneously.
Capital flows are circular. Earnings narratives are interdependent. Multiples are correlated.
If Nvidia were to experience a structural repricing because AI compute economics changed, the impact would likely cascade:
Hyperscaler revenue expectations would compress
AI-driven CapEx assumptions would reset
Semiconductor supply chains would reprice
Growth multiples across mega-cap tech would contract
Nvidia is not just 7 to 8 percent of the index.
It is entangled with the earnings logic of the other largest constituents.
The exposure is systemic, not isolated.
The AIG Analogy, Without the G
In 2008, AIG was not the largest bank. It was the insurance layer underneath the financial system.
When housing collapsed, AIG’s interconnected obligations forced an 85 billion dollar emergency intervention. Total support ultimately approached 180 billion dollars.
AIG was too interconnected to fail because it underwrote the system.
Today, Nvidia underwrites the AI stack.
Cloud buildouts.
Foundation model training.
Enterprise AI pipelines.
Unlike AIG, Nvidia’s fragility does not stem from leverage. It stems from concentration and narrative dependency inside a tightly coupled mega-cap ecosystem.
Why the Market Narrative Persists
Hyperscalers are investing tens of billions annually in AI infrastructure.
That capital expenditure requires justification.
The simplest justification is:
“We are not at AGI yet. We need larger models.”
But if current systems already exceed the median human across cognitive domains, the narrative shifts.
From endless scaling —> To deployment efficiency
From bigger clusters —> To embedded intelligence
If intelligence itself is no longer scarce, then perpetual GPU scarcity becomes a weaker thesis.
Frontier research will always demand high-end hardware.
But the marginal dollar of value creation may shift toward orchestration, optimization, and distribution.
In Closing
If AGI means perfect reasoning in every context, the debate will never end. The goalposts can always move.
If AGI means economically substituting for human cognition across domains at scale, the threshold is already behind us. That is visible in code bases, in customer operations, in legal workflows, and in executive hiring logic.
The market, however, is still pricing intelligence scarcity as though we are still waiting on the breakthrough.
That pricing supports a perpetual infrastructure story: bigger clusters, bigger chips, bigger data centers, bigger power plants.
But deployment is not training. Inference does not always require the latest greatest GPUs or perpetual retraining on the entire world’s information. Optimization, specialization, and inference-oriented silicon can push capability into cheaper, lower-power form factors.
Zero to One already happened. Everything now is One to N.
And when markets internalize that distinction, the valuation structure around AI infrastructure may change as dramatically as it rose.
And when that happens, we may discover that the real surprise was not that AGI arrived. It was that we had already been living with it.

About the Author: Dr. Steven Muskal is CEO and founder of Eidogen Sertanty, with more than four decades of experience in AI driven drug discovery. He holds a Ph.D. in Chemistry from UC Berkeley (1991), where his thesis focused on neural networks for protein structure prediction.
For a music mix sample - I thought this one might be fitting - a blast from the past. The first time for most, even with fade-out… RickL (Vocals), TimD (Guitar/Volcals), GeoffS (Bass/Vocals)