


By Steven Muskal, Ph.D. | The Renaissance Circle | June 2026 | stevenmuskal.com
My AI Steve system now preps me for podcasts. Before Jonas Lee walked into my studio, AI Steve had already generated a spoken intro, talking points, and a gentle critique: “Dude, you need to start intro-ing your people a little bit more.”
So here’s the intro, AI-generated and human-delivered:
Welcome to The Renaissance Circle. I’m Steve Muskal, CEO of Eidogen-Sertanty, and I’ve spent the last forty years at the corner of AI, chemistry, and drug discovery. My guest is Jonas Lee, a scientist who came up through the same laboratory I did at UC Berkeley: the lab of Professor Sung-Hou Kim. Jonas and I didn’t overlap in the lab. He arrived about twelve years after I left. But we’re connected by the same intellectual DNA: the conviction that if you understand the shape of a molecule, you understand how to fix it.
And then Jonas parked in my parking spot. First podcast ever. Classic. Full discussion at the end.
• • •
The Kim Lab Connection
Professor Sung-Hou Kim’s lab at UC Berkeley trained generations of scientists who reshaped structural biology and drug discovery. I was there from roughly 1988 to 1991. Jonas arrived in 2003. We never overlapped, but the lab’s DNA runs through both of our careers.
When I recently had a video call with Sung-Hou and his wife Rosie, I was stunned. He’s 92. He looks better than people I know in their 60s. Same pause, same thoughtfulness, same way of asking questions that I remembered from three decades ago.
Jonas and I reconnected through email ahead of the Kim Lab Alumni Reunion, and I realized this scientist with a pedigree from Illinois, Berkeley, Caltech, Amgen, and Johnson & Johnson lived just a few miles from me in Southern California. The podcast was inevitable.
From Lasers to Membranes: Jonas’s Origin Story
Jonas grew up partially in South Korea during the 1980s economic boom. His father, originally a marine biologist turned petroleum engineer, lost his job during the oil industry downturn that followed the 1980s oil production glut and price collapse, a whiplash effect that emerged after the shortages and price spikes associated with the 1970s energy crises. The family moved to Korea right at the inflection point of massive economic growth. They returned to the US when Jonas was in middle school.
At the University of Illinois Urbana-Champaign, Jonas got his first taste of protein structure work, shooting lasers at protein molecules to map energy landscapes of folding. The approach never fully worked, but the problem stuck.
At Berkeley in Sung-Hou’s lab, he worked on membrane protein structures, chemotaxis receptors, and attempted GPCR structure determination. Six years of PhD work on some of the hardest structural biology problems in existence.
Then Caltech for a four-and-a-half-year postdoc under Douglas Rees, where he finally solved an ABC transporter structure, earning a first-author Science paper.
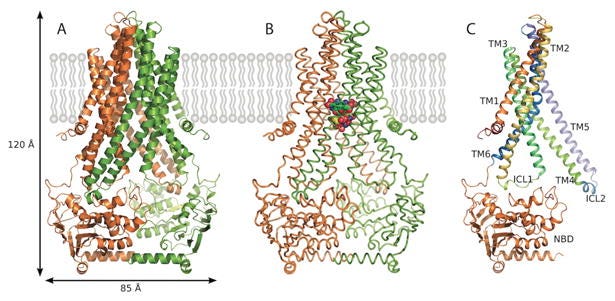
With a first-author Science paper on membrane protein structure, Jonas applied to about fifty academic positions. He got one interview.
One of the positions he applied to, UC Santa Cruz, had 100 candidates giving seminars. Three seminars per week for twenty weeks straight.
This is the state of academic science. Brilliant, productive researchers with world-class credentials competing for positions that barely exist. The system is broken, and we’re losing talent because of it.
Big Pharma: Amgen and Janssen
Amgen hired Jonas during their restructuring period. They had acquired deCODE Genetics in Iceland, the homogeneous population study, and about a third of the phenotypic biomarkers they identified turned out to be membrane proteins. They needed someone who could produce these molecules at scale for compound screening.
At Janssen (J&J), Jonas joined the New Platforms and Technologies group, working on antibody engineering, phage display, large combinatorial DNA library construction, and automated single-clone output screening. The kind of multifaceted problem-solving where you have to think about DNA sequence space, selection processes, and what Jonas calls “the last mile problem” of figuring out which hits are actually correct.
Then Janssen reorganized his group into gene therapy. Jonas wasn’t interested.
“Gene therapy is more empirical,” he told me. “You have a biomarker, you design a plasmid, you infect, and hope you knock down the gene. Unlike protein engineering, where you really have to think about the problem.”
Encodia: The Proteomics Moonshot
Encodia was trying to do for protein sequencing what Illumina did for DNA. The concept: denature proteins, cut them into peptidic fragments, bind them to a surface with individual DNA barcodes, then use engineered protein recognizers to identify amino acids at the N-terminus one at a time, transferring DNA tags at each step. Read up to 10-12 amino acids per fragment, across millions of fragments in parallel.
It was ambitious. It raised $75 million. And it shut down in January 2026.
I asked Jonas whether I would have invested. Honestly, probably not. The number of technical challenges was enormous, the story was deeply complicated, and the total addressable market for a tools-based company selling to pharma felt limited. But the people were among the smartest Jonas had ever worked with, and that’s what drew him in.
AI in Drug Discovery: The Regression Problem
When I asked Jonas what company he’d start if money were no object, his answer surprised me. Not some novel biology. AI for drug discovery, specifically using existing models like David Baker’s RF diffusion systems to find the gaps.
RFdiffusion can generate novel proteins that bind to target molecules:
Here RFdffusion generates a novel protein that binds to the insulin receptor:
His framing: AI is fundamentally big regression. The models already have the knowledge fitted in. The profitable path is finding the reliable memorization points and probing the spaces around them that haven’t been drugged yet.
“As long as you deviate enough to be novel, that’s actually a really easy space to target,” he said.
I pushed back. These models are content-dependent. AlphaFold had a few hundred thousand protein structures to learn from. But we still don’t have good quality data for protein-protein interactions, multi-protein complexes, small molecule-protein interactions, or peptide structures at any meaningful scale.
THE CONTENT IS (MAKES) KING THESIS
The platform (AI, neural networks, whatever you call it) is the tool. The data is what makes it work. Without good quality content, even the best algorithms produce garbage. This has been true since my 1991 neural network thesis at Berkeley, and it’s still true with AlphaFold today.
The China Question
Jonas laid it out bluntly. His point was not that Chinese CROs magically make biology move faster. The rate-limiting steps in many large-molecule programs remain the same everywhere. Instead, their advantage often comes from responsiveness, flexibility, and willingness to rapidly execute additional experiments that help difficult projects move forward:
Chinese CROs offer comparable pricing to American ones (within 10-20%)
For core biologics programs, overall timelines are often constrained by cells, animals, and other experimental bottlenecks. However, Chinese CROs are dramatically faster and more responsive when additional in vitro experiments, characterization studies, and project-support work are needed.
The flexibility is incomparable: American CROs require contracts for any change; Chinese CROs said “Okay, we can do it for free” and delivered in one week
There are five to ten times more people working in biotech in China, many as smart or smarter, working longer hours, with all the infrastructure already built
If China closed its borders, it could run independent biotech research end-to-end; if the US embargoed Chinese materials, American pharma companies would collapse
This isn’t alarmist. It’s the reality of where manufacturing and early-stage capabilities have migrated. The opportunity is in the spaces China hasn’t prioritized yet: rare diseases, novel targets, and collaborative models that leverage Chinese CRO infrastructure with American entrepreneurial capital.
The Case for Open Source in Pharma
Every pharma company thinks they’re doing something different. They’re not. Amgen and J&J have roughly 90% target overlap. Jonas confirmed this from having worked at both.
Having spent much of the early 1990s at Molecular Design Limited (MDL), I had a unique vantage point. My role took me around the world, visiting virtually every major pharmaceutical company and a substantial number of biotechnology firms. What struck me was not how different these organizations were, but how remarkably similar they were.
Medicinal chemists are trained from the same textbooks, attend the same conferences, read the same journals, and draw from many of the same pools of commercially available starting materials. Most organizations are understandably risk-averse. Few pursue programs unless there is already a published target hypothesis, a body of supporting literature, or competitive validation. The result is an industry that often converges on the same ideas at roughly the same time.
This creates an extraordinary amount of redundancy. Multiple organizations invest hundreds of millions of dollars pursuing nearly identical targets, mechanisms, and chemical scaffolds, frequently without knowing how many parallel efforts are underway elsewhere. From a societal perspective, the duplication is inevitable, wasteful, and, at times, almost absurd.
Many of the industry’s most important breakthroughs do not originate inside large pharmaceutical companies. Instead, they emerge from academic laboratories, small biotechnology startups, and entrepreneurial scientists willing to pursue unconventional ideas. Large pharmaceutical organizations excel at development, regulatory execution, manufacturing, commercialization, and global distribution. Their discovery organizations often contain exceptional scientists, but increasingly the industry’s most transformative innovations are licensed, partnered, or acquired after the foundational scientific risk has already been taken elsewhere.
This observation forms part of the case for greater openness in biomedical research. If thousands of highly trained scientists are already working from the same literature and building upon the same biological knowledge, it is worth asking whether a more collaborative, transparent, and open-source model could reduce duplication, accelerate progress, and allow resources to be directed toward genuinely novel problems rather than repeatedly rediscovering the same ones.
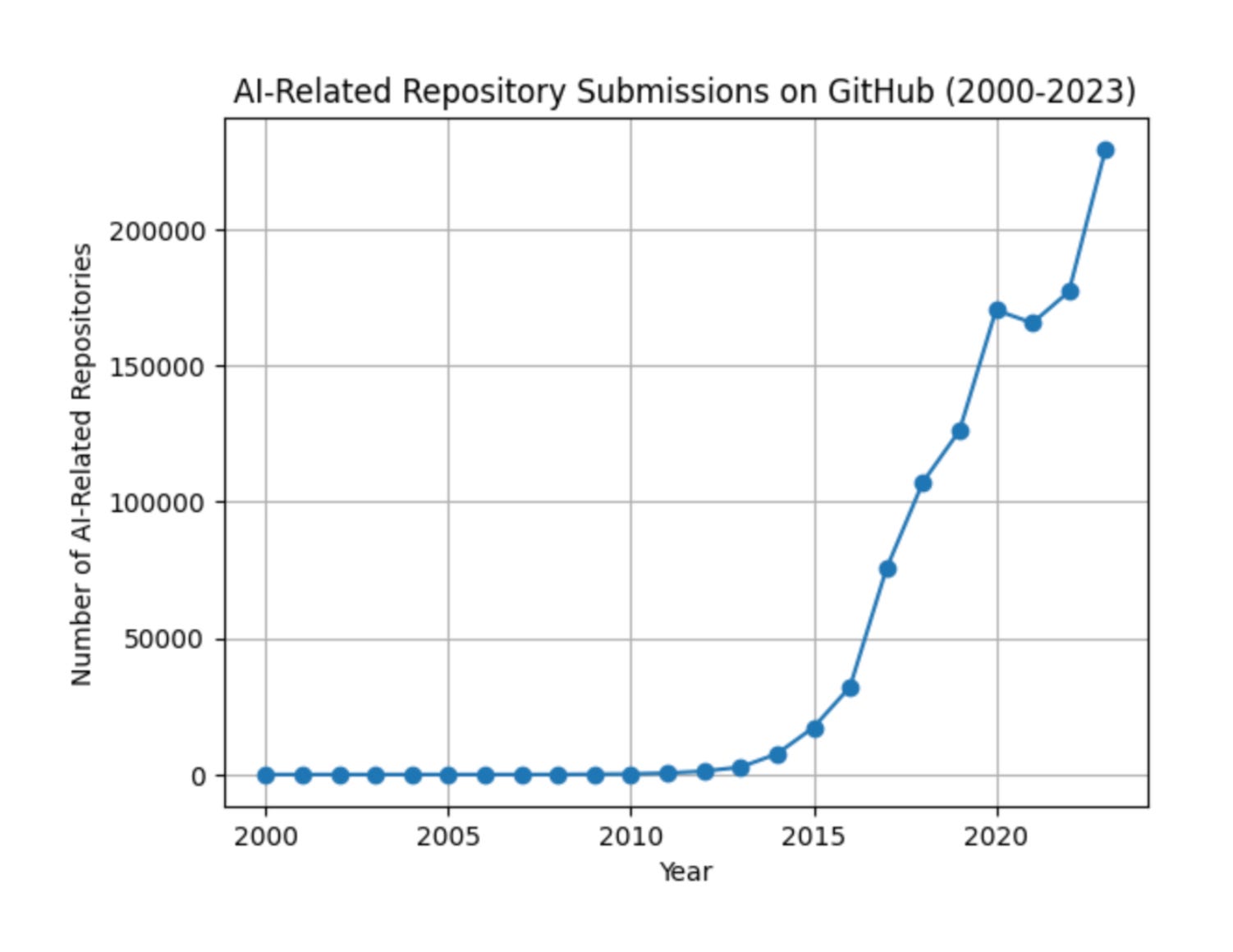
Meanwhile, the software industry exploded when it went open source. Google published “Attention Is All You Need” and gave it to the world. Our entire economy is making a bet on technology that came from sharing.
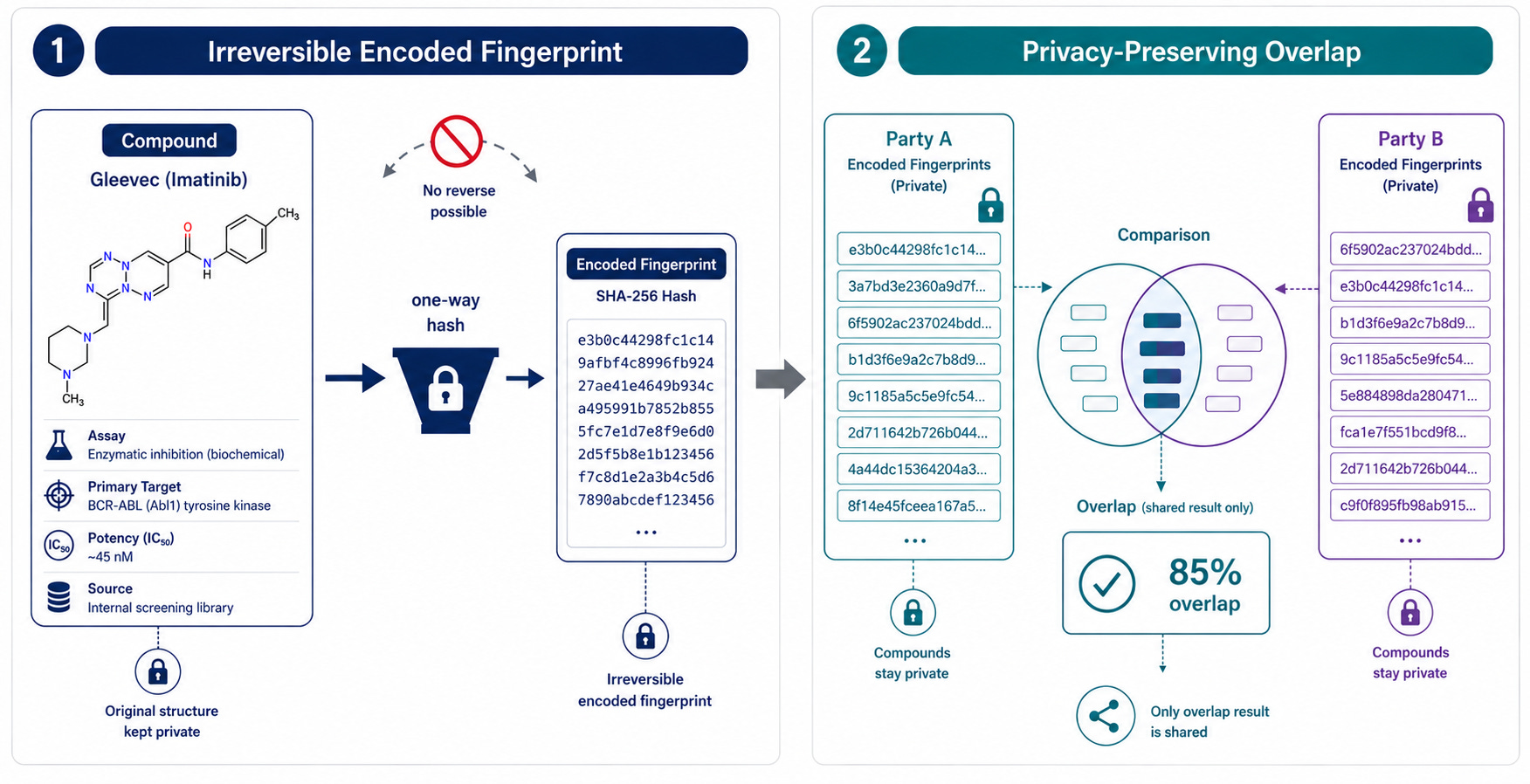
I built a proof of concept: hash a molecule and biological data point into an irreversible fingerprint. Two companies can compute their overlap without revealing what they have. If Amgen and J&J did this across their repositories and found 80% overlap, maybe they’d finally talk about filling each other’s gaps.
Pharma will never voluntarily share. But China might force the issue. Just as DeepSeek and Alibaba went open source in AI, Chinese biotech may lead the same revolution in pharma data sharing.
There is another force quietly working against the traditional pharmaceutical model: the accelerating pace of knowledge diffusion. Patents made perfect sense in a world where developing a medicine required decades of effort, massive capital investments, and highly specialized infrastructure available to only a handful of organizations. But as AI lowers the cost of discovery, shortens development cycles, and makes sophisticated scientific reasoning broadly accessible, the relative value of intellectual property barriers begins to diminish. In the AI industry, we rarely see companies winning through patents alone. OpenAI, Anthropic, Google, xAI, and others compete primarily by building better models, moving faster, and attracting stronger talent. The advantage comes from execution rather than exclusion. Biology may not follow exactly the same trajectory, but the direction is becoming harder to ignore. As discovery becomes cheaper, faster, and more distributed, competitive advantage may increasingly arise from the ability to learn, iterate, and execute rather than from the ability to lock knowledge away.
Prevention Is the Real Frontier
Jonas’s father passed away from cancer. He spoke candidly about how the first years of treatment were manageable, but eventually “you are not even living anymore. You are just under the drug’s influence.”
I cited Prof. Nathaniel Gray at Stanford: “More lives have been saved in cancer by not smoking than all the chemotherapies, all the cancer treatments, everything ever done, combined.”
Prevention is obvious. Everyone agrees. Yet we don’t do it.
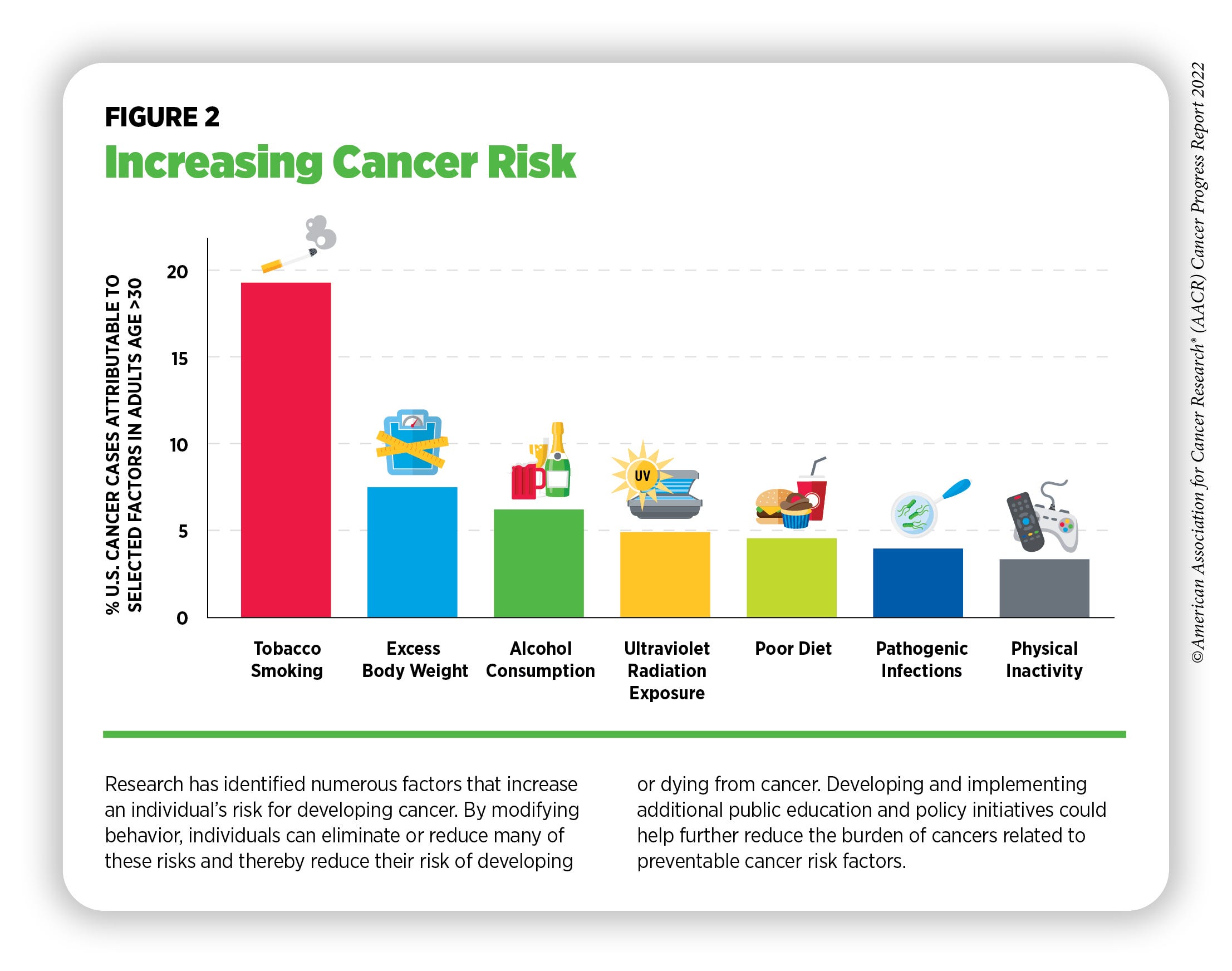
Jonas had an interesting insight on why Ozempic works as a business model for quasi-prevention: it has a clear phenotypic marker (weight). Cancer prevention drugs would never achieve the same adoption because cancer is probabilistic with no visible trait until malignancy. But aging? If you could take a monthly shot that visibly reduced wrinkles, adoption would be massive.
The next Ozempic might be an anti-aging drug with visible results.
Capital Misallocation and What Comes Next
Jonas told a story about his friend who worked extremely hard building an Airbnb business. Jonas put the same capital into VOO and QQQ and did nothing. He’s 100% ahead.
“The reward structure is completely misaligned,” Jonas said. “If doing nothing is more financially incentivized than doing something right, the system has a lot of problems.”
When I asked what he’d do if money weren’t an issue, Jonas surprised me. Not start a company. Go back to graduate school. Work on the riskiest, most frontier research. Solve difficult problems in different dimensions.
There’s something both humble and ambitious about that answer. A scientist with decades of experience across academia and industry, who just wants to go back to the bench and tackle the hardest unsolved problems.
• • •
The Reunion
The Kim Lab Alumni Reunion is August 1, 2026. Sung-Hou Kim is 92 and still sharp. George Church is attending. Joel Sussman is Attending. A whole cohort of scientists who passed through one lab and went on to reshape fields.
I started the neural network project in that lab in 1991. The concept won a Nobel Prize in Chemistry thirty-three years later with AlphaFold. Jonas spent six years there on membrane proteins and went on to work at three of the most sophisticated protein engineering operations in the world.
Same lab. Different decades. Same conviction: understand the shape of a molecule, and you understand how to fix what’s broken.
Full Discussion

Steven Muskal, Ph.D. is the CEO of Eidogen-Sertanty, Inc. - a drug discovery informatics company. He has spent four decades working at the intersection of computational biology, AI, and drug discovery. He writes about AI, health, and the intersection of biology and technology at stevenmuskal.com
For a couple mix vids, we had a very fun acoustic mix with RonF (vocals/guitar) DanM (Vocals/Guitar), and TimL (Bass/Vocals). My forearms are still sore from I'm On Fire - always fun when someone calls a song with a 189-190 BPM tempo early in a 22 song session...Not!


